At EPFL, the Library Research Data Management team is at your disposal to provide you with expert advice, support, and solutions. This page introduces you to the various forms of data publication (data platforms and/or data journals) with some helpful tools and two useful tables for the most used platforms and journals at the EPFL.
To make your data or code visible and openly available, you should publish them in a citable form, which preserves and enables access to this type of research output.
Indeed, many funding agencies, including the SNSF, expect its funded researchers to deposit their data and metadata onto existing public repositories in formats anyone can find, access, and reuse without restriction.
Data publication
There are essentially two ways to publish your research data:
1 | Data dissemination platforms
There exist various types of data (and code) dissemination platforms. You can find here below definitions and examples for the main types of platforms used to disseminate research data or code.
- In short: Commercial or institutional online platforms allowing to store, version, publish, retrieve and collaborate on active code
- Extended: Online platform that simplifies the version control of code, allowing developers to submit patches of code in an organized, collaborative manner. It can also be used for backup of the code. Sometimes it acts as a web hosting service where developers store their source code for web pages. Often, source code repository software services and websites support bug tracking, mailing lists, version control, documentation, and release management. Developers generally retain their copyright when software is posted to a code hosting facility and can make it publicly accessible.
- Some examples: GitHub, GitLab EPFL, etc.
- Not for: Code repositories are not usually designed for data/code preservation nor for data analysis purposes.
- In short: Institutional or commercial online platform allowing to aggregate, combine, analyze and visualize active datasets (data and/or code)
- Extended: Online platform used to perform analysis, retrieve, combine, interact with, explore, and visualize data. The underlying data can originate from various sources (e.g. data banks, user-provided, API, etc.), online or offline. The main scope of a data analysis platform is to turn every data into actionable insights, other than overcoming possible inadequacies of a relational database or table. As these platforms embed the tools for accomplishing meaningful data transformations, they are usually focused on specific research domains, and use consequent formats, algorithms, and processes. Others, especially the ones used for code scripts, can be more generic.
- Some examples: Renku, ELN EPFL, Open Data Cube, etc.
- Not for: Data analysis platforms are not usually designed for data preservation nor for data publication purposes.
- In short: Mostly institutional online platforms allowing to preserve and retrieve cold data
- Extended: Storage infrastructure enabling the long-term retention and reusability of data. Provides secure, redundant locations to securely store data for future (re)use. Once in the archived data management system, the data stays accessible and the system protects its integrity. A data archive is a place to store data that is deemed important, usually curated data, but that doesn’t need to be accessed or modified frequently (if at all). Most institutions use data archives for legacy data, or data of certain value, or to meet regulatory standards. Data are not usually findable by external users.
- Some examples: ACOUA, ETH Data Archive, OLOS, etc.
- Not for: Data archives are not usually designed for data publication nor for data analysis purposes.
- In short: Institutional or commercial online platforms allowing to store, aggregate, discover, and retrieve cold data
- Extended: Collection of datasets for secondary use in research that allows processing many continual queries over a long period of time. Not to be confused with the organizations concerned with the construction and maintenance of such databases. Services and tools can be built on top of such a database, for development, compilation, testing, verification, dissemination, analysis, and visualization of data. Normally part of a larger institution (academic, corporate, scientific, medical, governmental, etc.) is established to serve the data to users of that organization. A data bank may also maintain subscriptions to licensed data resources for its users to access the information.
- Some examples: DBnomics, Channelpedia, DataLakes, etc.
- Not for: Data banks are not usually designed for data preservation nor for data analysis purposes.
- In short: Institutional or commercial online platforms allowing to preserve, publish, discover and retrieve cold datasets (data and/or code)
- Extended def.: Online infrastructure where researchers can submit their data. Allows to manage, share, and access datasets for the long term. Can be generic (discipline-agnostic) or specialized (discipline-specific): specialized data repositories often integrate tools and services useful for a discipline. The main purpose is to preserve data to make it reusable for future research. Data repositories may have specific requirements concerning: research domain; data re-use and access; file format; data structure; types of metadata. They can also have restrictions on who can deposit data, based on: funding; academic qualification; quality of data. Institutional data repositories may collect a university or consortium of university researchers’ data.
- Some examples.: Zenodo, Materials Cloud, Dryad, etc.
- Not for: Data repositories are not usually designed for data analysis nor for code versioning purposes.
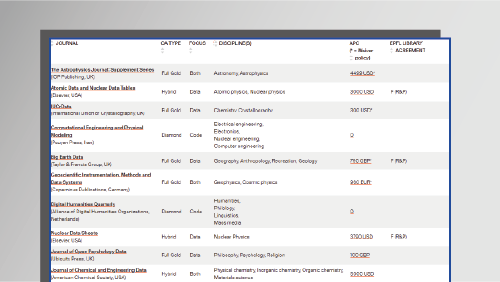
2 | Data journals
If you want to highlight the importance of your data and be citable for this publication, you might also consider writing a data paper, i.e. a peer-reviewed paper describing a dataset as research output.
Data journals allow focusing on the description of the data, its context, the acquisition methods, as well as its actual and potential use (rather than presenting new hypotheses or interpretations).
As data journals are always Open Access, an Article Processing Charge (APC) has to be paid by the author for the publication costs. It is possible to request the Library’s financial support to cover part of the APC.
Some examples:
- Scientific Data (Springer Nature Group)
- Data in Brief (Elsevier)
- Journal of Physical and Chemical Research Data (AIP)
- Journal of Open Research Software (Ubiquity Press)
- GeoScience Data Journal (Wiley)
Finding the right one
When choosing the platform or journal that best fits your needs, consider the following elements:
- Check funders’ requirements and recommendations;
- Preferably choose platforms providing persistent IDs (DOI, for instance);
- Check compliance with your data protection and licensing, if needed (see also here);
- Look for certification as a trustworthy digital platform if possible: this grants data preservation in the long term;
- Disciplinary repositories are generally a good choice, for directly reaching target communities and peers. However, they require a lot of resources (human, machine, time) and do not always meet interoperability standards;
- Multi-disciplinary repositories accept any type of data and enable broader visibility and interoperability. However, they do not target specific communities and therefore are not the reference in those fields.
A great resource to identify the good repository is re3data (see also below).
Also check the list of FAIR repositories provided by the HES·SO.
Overview of the most used platforms by EPFL researchers
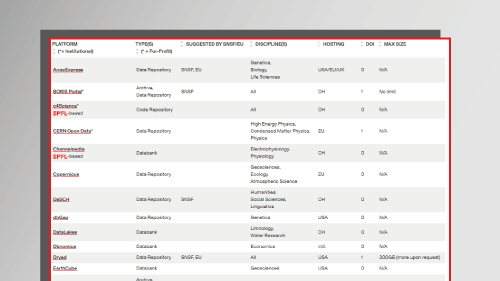
Useful tools
Zenodo
Repository operated by CERN covering all scientific disciplines. It offers free data submission for any research as long as it is openly published. In addition, DOI are systematically attributed to records, making them cleanly citable. Another notable feature is its integration with GitHub, enabling to capture, preserve and cite Git repositories.
EPFL Community on Zenodo
If you publish your datasets or other research material on Zenodo as an EPFL member, we invite you to associate them with the EPFL Zenodo Community. The Library RDM team will review the dataset according to the Curation Policy, enabling better visibility and facilitating the dissemination of information.
Materials Cloud
Web platform and data repository, designed to assist Materials Scientists in the life-cycle of their computational projects. Openly developed on the materialscloud-org GitHub repository.
Dryad
Curated general-purpose scientific data repository. All records in Dryad are associated to published articles, and a data publishing fee is requested for deposition. DOI are attributed systematically.
Figshare
Platform offering data deposition and access for all disciplines, and attributes systematically DOI. Unlike Zenodo and Dryad, Figshare is a commercial repository, belonging to Macmillan Publishers.
re3data
The global search engine for data platforms. It covers research data repositories and platforms from different academic disciplines and includes repositories that enable permanent storage, access to data sets to researchers, funding bodies, publishers, and scholarly institutions.