
Image Descriptors and Keypoint Detection
We propose deep-learning solutions to extract image features and keypoint locations for applications such as image matching and 3D reconstruction. Opposed to hand-crafted features, such as SIFT, invariances are learned from example images.

Deformable Surface Modeling
In this line of work, we develop template-based methods to infer the 3D shape of surfaces from single images. We applied these monocular reconstruction methods to reconstruct the dynamics of diverse objects, for instance, baseballs, sails, and garment.

Tracking and Modeling People
Reconstructing the dynamic motions of humans is one of the most challenging reconstruction problems in computer vision. We develop methods to track individual people in a crowd, detect actions in group activities, and reconstruct the 3D human pose consistently across long videos.
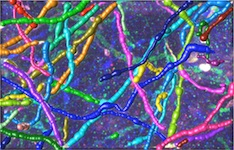
Modeling the Brain
Understanding the functionality and layout of the human brain is a longstanding research goal in neuroscience. We develop methods to study the position and connection of neurons and other structures, for automatic segmentation and for tracking formations over extended periods of time.
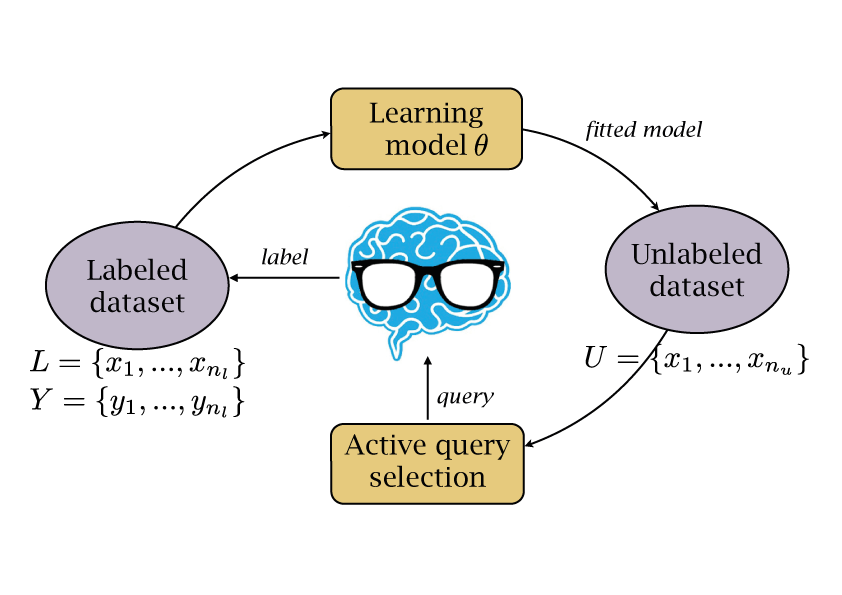
Machine Learning for Biomedical Imaging
Many segmentation and annotation tasks can be automated by machine learning approaches, that are trained on manually labeled examples. We propose methods to reduce the required number of labeled examples by exploiting labels in other domains and by selecting the most relevant images for labeling.

Unmanned Aerial Vehicles
To avoid collisions and other threads, we propose approaches to detect flying objects such as UAVs and aircrafts, even when they only occupy a small portion of the field of view, are possibly moving against complex backgrounds, and are filmed by a camera that itself moves.
3D Object Tracking
Many Robotics and Augmented Reality applications require to accurately estimate 3D poses. We build 3D object tracking frameworks based on the detection and pose estimation of discriminative parts of the target object. These work in typical AR scenes with poorly textured objects, under heavy occlusions, drastic light changes, and changing background.
Domain Adaptation
Our goal is to make it possible to use Deep Nets trained in one domain where there is enough annotated training data in another where there is little or none. We introduce a network architecture that preserves the similarities between domains where they exist and models the differences when necessary.
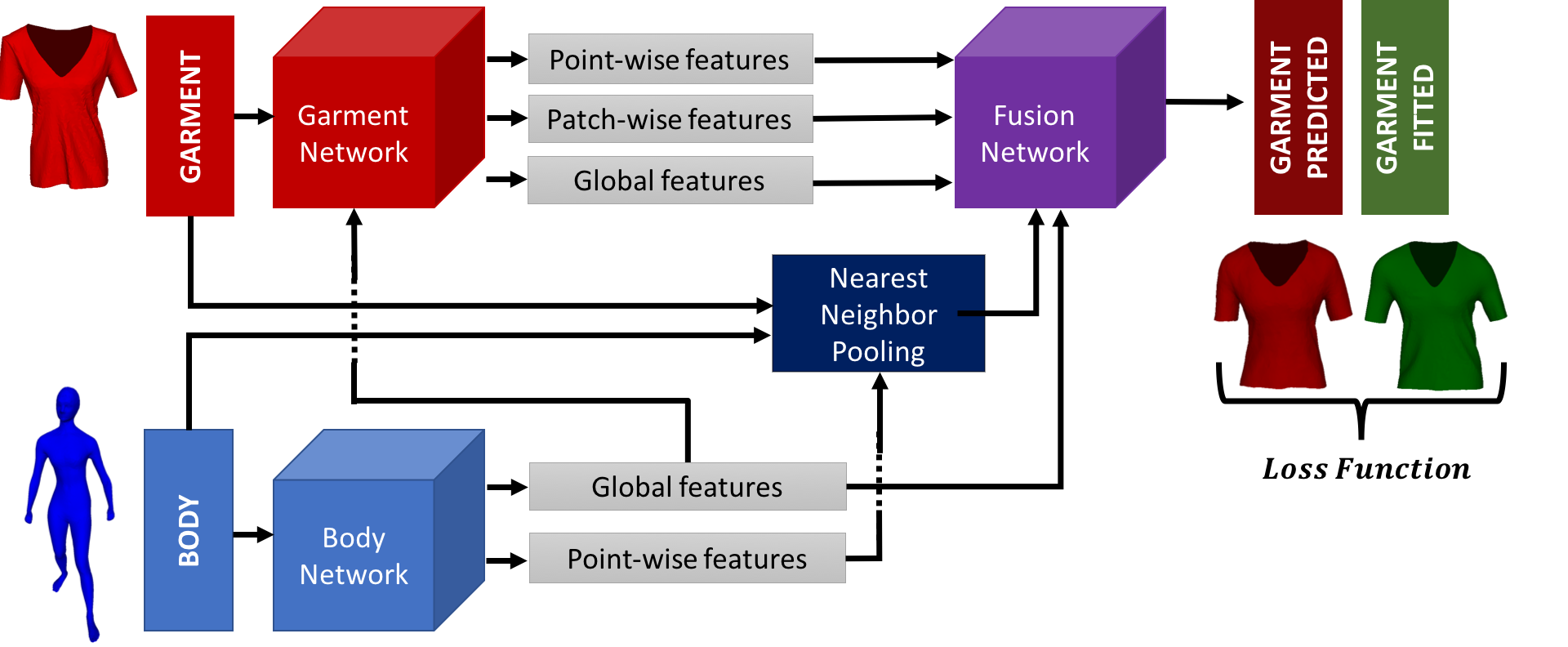
Garment Simulation
While Physics-Based Simulation (PBS) can highly accurately drape a 3D garment model on a 3D body, it remains too costly for real-time applications, such as virtual try-on. By contrast, inference in a deep network, that is, a single forward pass, is typically quite fast. Our goal is to reproduce the results of physically-based simulations by (…)
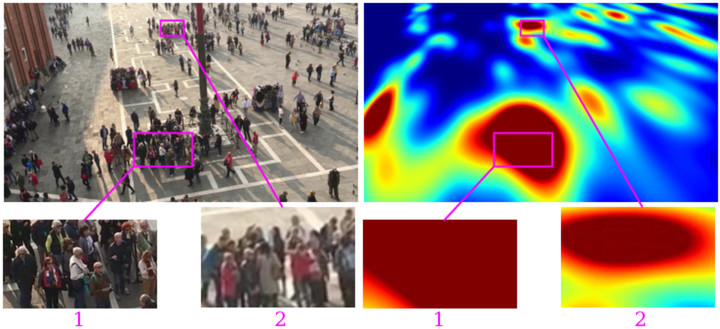
Crowd Counting
Given images of a crowd, we estimate its density and the number of people.

6D Object Pose Estimation in Space
Estimating the relative 6D pose of an object, that is, its 3 rotations and 3 translations with respect to the camera from a single image is crucial in many applications.Most traditional methods address this problem by first detecting keypoints in the input image, then establishing 3D-to-2D correspondences, and finally running a Perspective-n-Point algorithm. Unfortunately, this (…)
Completed Projects
- Randomized Trees and Ferns: Keypoint Matching by Classification
- Multi-Scale Rendering of Huge 3D Volumes
- Sail Modeling
- Robust Golf Club Tracking
- The Haunted Book
- Faces from Single Video Sequences
- An All-In-One Solution to Geometric and Photometric Calibration
- Implicit Surfaces for Surface Reconstruction
- Implicit Surfaces for Body Tracking
- Real-Time 3-D Tracking
- Hierarchical Joint Limits
- Motion Models for Body Tracking
- DAISY: A Fast Local Descriptor for Dense Matching
- Large Scale Camera Calibration
- Efficient Large Scale Multi-View Stereo for Ultra High Resolution Image Sets