Dynamic and Scalable Large Scale Image Reconstruction
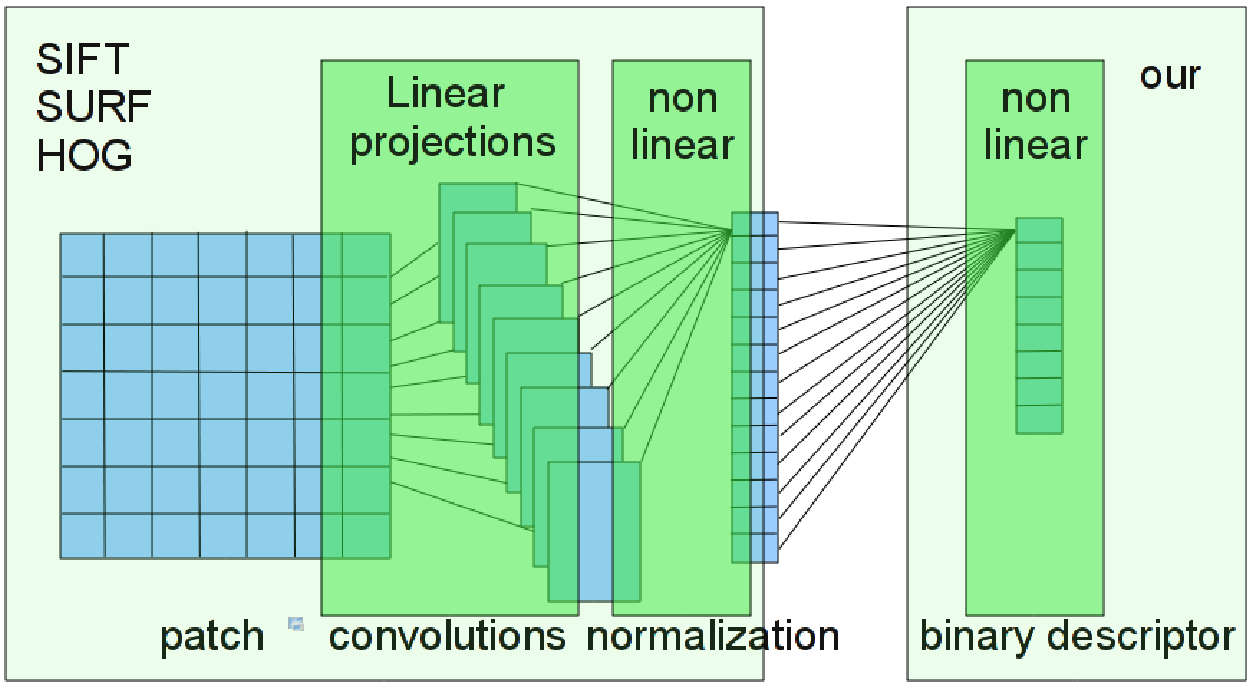
SIFT-like local feature descriptors are ubiquitously employed in such computer vision applications as content-based retrieval, video analysis, copy detection, object recognition, photo-tourism and 3D reconstruction.
Feature descriptors can be designed to be invariant to certain classes of photometric and geometric transformations, in particular, affine and intensity scale transformations. However, real transformations that an image can undergo can only be approximately modeled in this way, and thus most descriptors are only approximately invariant in practice.
Secondly, descriptors are usually high-dimensional (e.g. SIFT is represented as a 128-dimensional vector). In large-scale retrieval and matching problems, this can pose challenges in storing and retrieving descriptor data.
We map the descriptor vectors into the Hamming space, in which the Hamming metric is used to compare the resulting representations.
This way, we reduce the size of the descriptors by representing them as short binary strings and learn descriptor invariance from examples.
We show extensive experimental validation, demonstrating the advantage of the proposed approach.
The training and evaluation data was obtained by using our calibration pipline Dynamic and Scalable Large Scale Image Reconstruction. Further evaluation was done on Lidar ground truth data as obtained by On Benchmarking Camera Calibration and Multi-View Stereo for High Resolution Imagery.
Results
We trained our binray descriptor on the Lausanne database.
Venice internet image evaluation dataset: example patches corresponding to the same 3D point (click to enlarge).
 |
 |
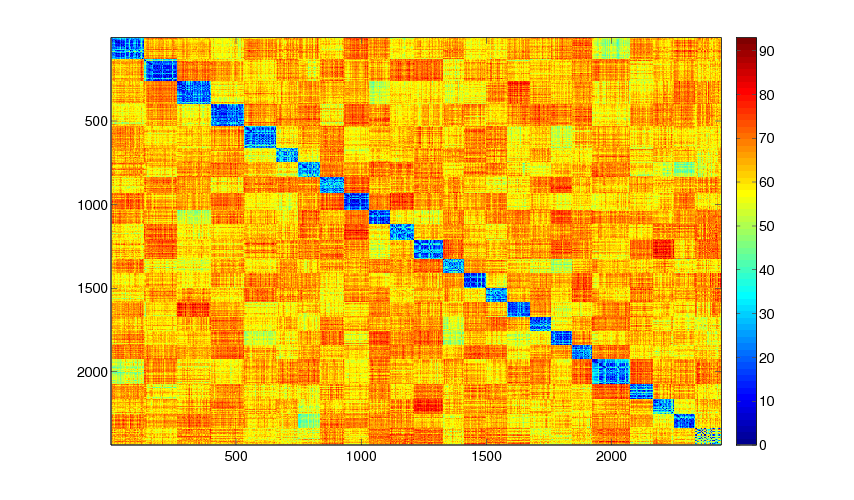
Confusion matrix for the 24 largest tracks for the Venice dataset (click on images to enlarge).
| SIFT L2 norm | LDAHash Hamming distance |
 |
 |
Calibration results using the binary descriptors
Lausanne cathedral statue
Sequence contains 127 18-Megapixel images of a statue at different scales.
| Result of the calibration: camera positions and sparse 3D points | Result of the calibration: 3D points (zoom) |
 |
 |
Lausanne cathedral side entry
Sequence contains 288 18-Megapixel images of the Lausanne cathedral side entry at different scales.
| Result of the calibration: camera positions and sparse 3D points | Result of the calibration: 3D points (zoom) |
 |
 |
Lausanne cathedral side entry
Sequence contains 288 18-Megapixel images of the Lausanne cathedral side entry at different scales.
| Result of the calibration: camera positions and sparse 3D points | Result of the calibration: 3D points (zoom) |
 |
 |
References
Main Reference
Please note that the publication lists from Infoscience integrated into the EPFL website, lab or people pages are frozen following the launch of the new version of platform. The owners of these pages are invited to recreate their publication list from Infoscience. For any assistance, please consult the Infoscience help or contact support.
LDAHash: Improved Matching with Smaller Descriptors
IEEE Transactions on Pattern Analysis and Machine Intelligence. 2012. Vol. 34, p. 66-78. DOI : 10.1109/TPAMI.2011.103.Related References
Please note that the publication lists from Infoscience integrated into the EPFL website, lab or people pages are frozen following the launch of the new version of platform. The owners of these pages are invited to recreate their publication list from Infoscience. For any assistance, please consult the Infoscience help or contact support.
Dynamic and Scalable Large Scale Image Reconstruction
2010. 23rd IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, U.S.A, June 13-19, 2010. p. 406-413. DOI : 10.1109/CVPR.2010.5540184.Please note that the publication lists from Infoscience integrated into the EPFL website, lab or people pages are frozen following the launch of the new version of platform. The owners of these pages are invited to recreate their publication list from Infoscience. For any assistance, please consult the Infoscience help or contact support.
On Benchmarking Camera Calibration and Multi-View Stereo for High Resolution Imagery
2008. IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, June 24-26, 2008. DOI : 10.1109/CVPR.2008.4587706.Please note that the publication lists from Infoscience integrated into the EPFL website, lab or people pages are frozen following the launch of the new version of platform. The owners of these pages are invited to recreate their publication list from Infoscience. For any assistance, please consult the Infoscience help or contact support.
Efficient Large Scale Multi-View Stereo for Ultra High Resolution Image Sets
Machine Vision and Applications. 2012. Vol. 23, num. 5, p. 903-920. DOI : 10.1007/s00138-011-0346-8.Contacts
| Christoph Strecha | [e-mail] |
| Alexander M. Bronstein | [e-mail] |
| Michael M. Bronstein | [e-mail] |
| Pascal Fua | [e-mail] |