The task of traditional Machine Learning is to search for the best model given some data, while the task of Active Learning is to search for a small set of informative samples that restricts search space as much as possible. The Active Learning research question is if the machines can learn faster and more efficient if they are given an opportunity to ask questions.
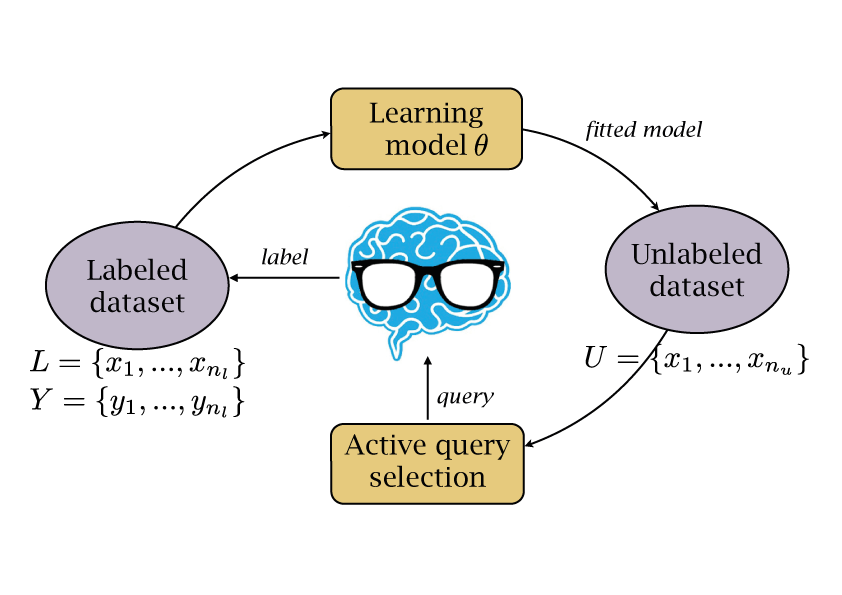
In a typical Active Learning scenario we start with a few training samples L, Y in a labeled dataset and we use them to learn the parameters theta of a model. Then, a large unlabelled dataset U is passed to a fitted model and predictions are made. The intrinsic part of an active learning algorithm is a query selection strategy. It is responsible for selecting the best query that helps to minimise the needed input from a human annotator. It can be based on different criteria that will be presented next. After a new sample has been labeled by annotator, it is added to the labeled dataset and a procedure is repeated again.
Learning Active Learning
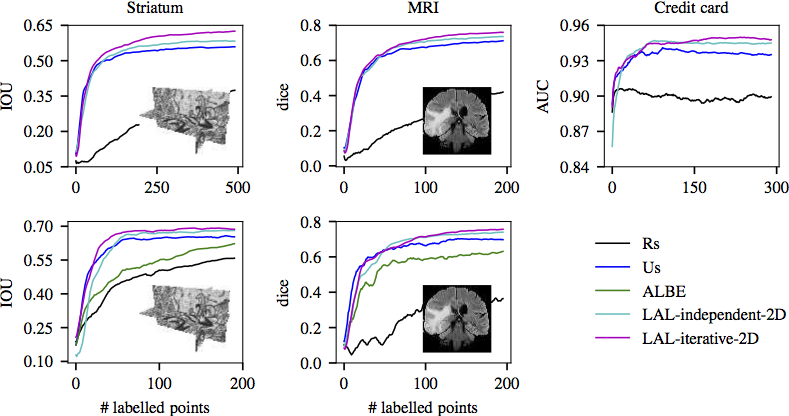
Over the years, many AL strategies have been developed for various classification tasks, without any one of them clearly outperforming others in all cases. Thus, we suggest a novel data-driven approach to active learning (AL): Learning Active Learning (LAL).
Learning Active Learning uses properties of classifiers and data to predict the potential error reduction. Given a dataset with ground truth, we simulate an online learning procedure using a Monte-Carlo approach. Our goal is to correlate the change in test performance with the properties of the classifier and of newly added datapoint. The features for the regression are not domain-specific and this enables to apply the regressor trained on synthetic data directly to other classification problems.
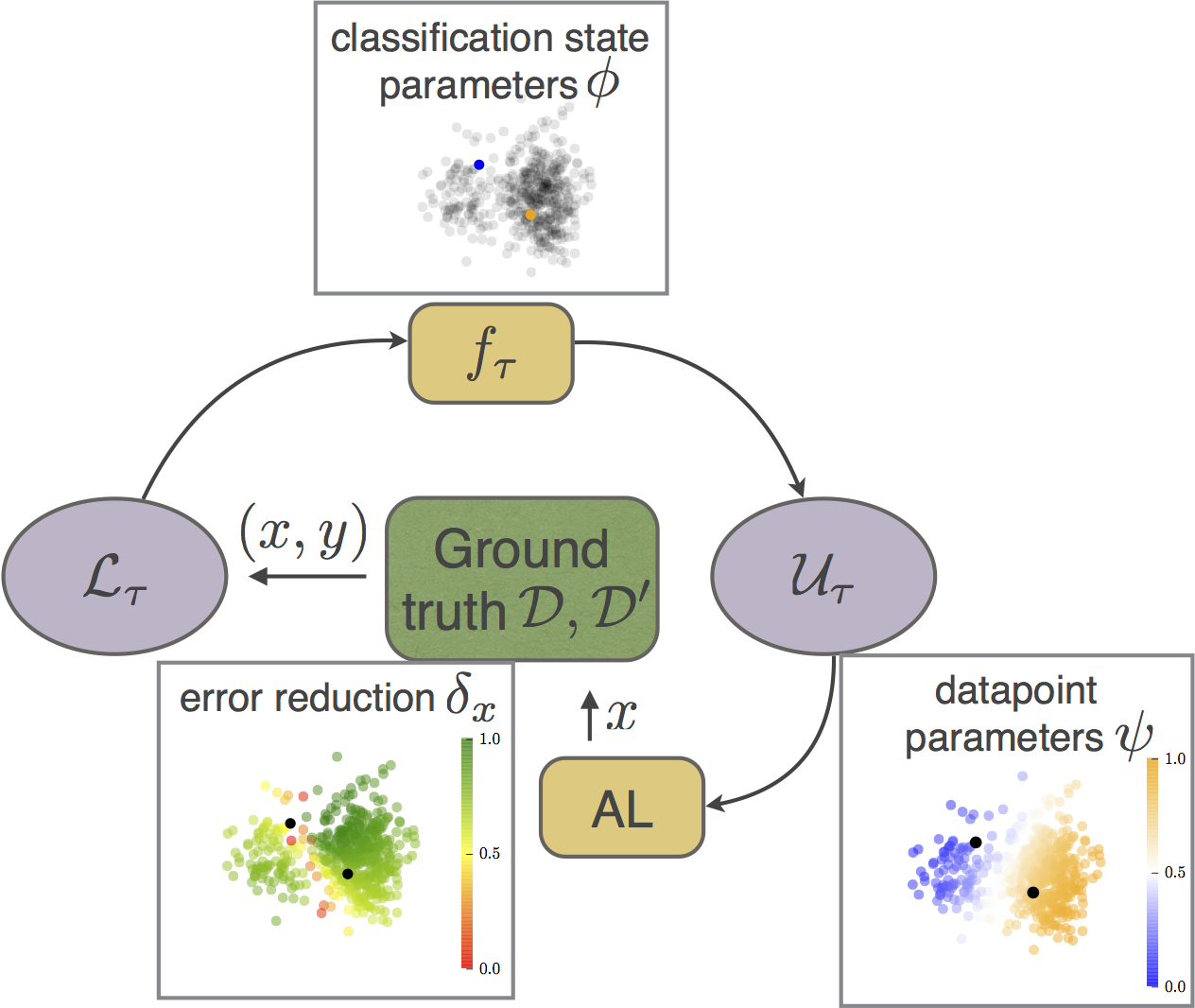
Our approach to AL is data-driven and can be formulated as a regression problem. We model the dependency between the state of the learning and the expected greedy improvement of the test error. By formulating the query selection procedure as a regression problem we are not restricted to working with existing AL heuristics; instead, we learn strategies based on experience from previous AL outcomes. We show that a strategy can be learnt either from simple synthetic 2D datasets or from a subset of domain-specific data.
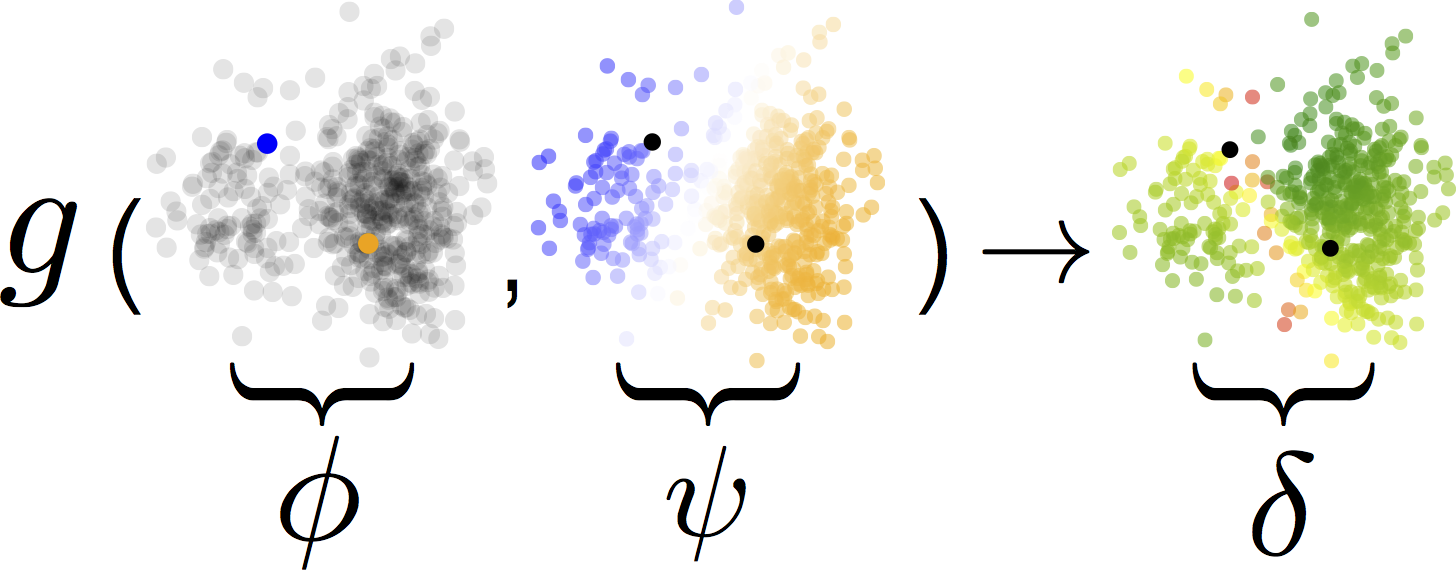
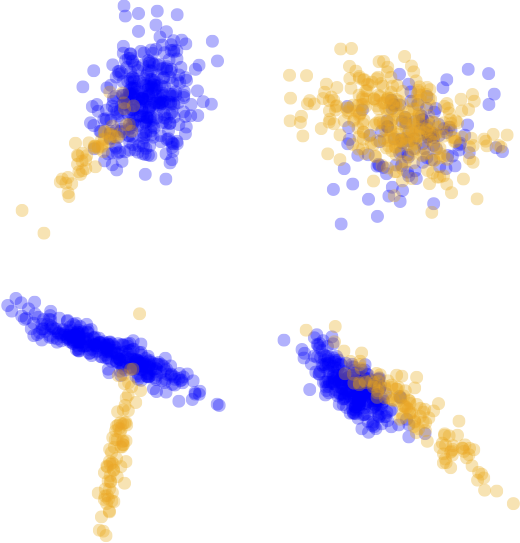
Our method yields strategies that work well on real data from a wide range of domains.
References
Please note that the publication lists from Infoscience integrated into the EPFL website, lab or people pages are frozen following the launch of the new version of platform. The owners of these pages are invited to recreate their publication list from Infoscience. For any assistance, please consult the Infoscience help or contact support.
Learning Active Learning from Data
2017. Conference on Neural Information Processing Systems (NIPS).Interview on TWiML&AI by Ksenia Konyushkova.
Code released on GitHub.
Poster from NIPS.
Segmentation
One of our tasks is to detect mitochondria. They are organelles that play an important role in cellular functioning: neuroscientists are interested in detecting and locating them as a source of energy.
The automatic mitochondria detection pipeline looks like the following. First, we oversegment 3D images and train a classifier on supervoxels with gradient boosted decision trees to distinguish between positive class that is mitochondria and negative class that is all the rest of the tissue.
To measure the quality of the segmentation we compute VOC score as a proportion of TP in TP, FP and FN. Unfortunately, acquiring training data is a current bottleneck in automatic segmentation methods.
However, using active learning strategies can let us to get to the same quality of the prediction with only 100 training samples against the whole dataset of 10000 datasamples.
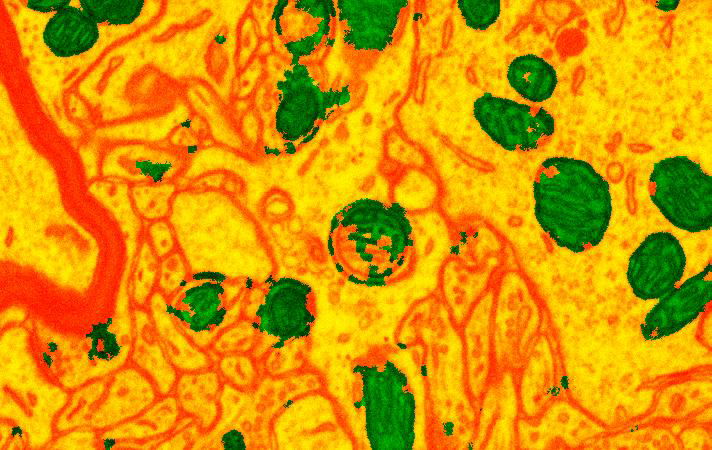
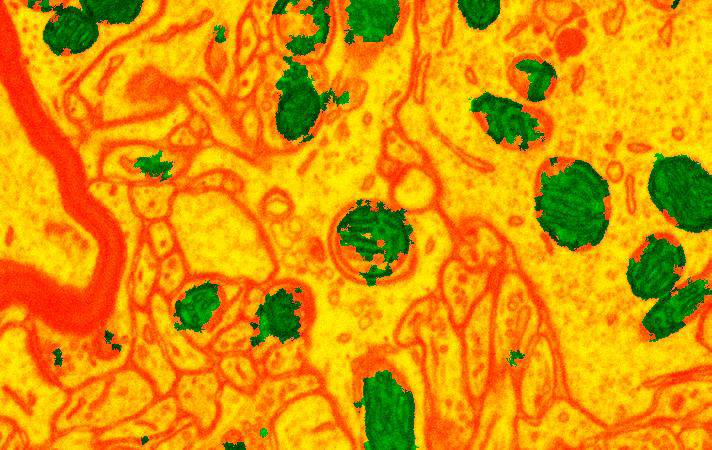
On the left: prediction with 100 actively selected datapoints, on the right: prediction with the whole dataset of size 10000. There is no noticable difference in quality of segmentation.
References
Please note that the publication lists from Infoscience integrated into the EPFL website, lab or people pages are frozen following the launch of the new version of platform. The owners of these pages are invited to recreate their publication list from Infoscience. For any assistance, please consult the Infoscience help or contact support.
Introducing Geometry in Active Learning for Image Segmentation
2015. international conference in Computer Vision, Santiago, Chile, December 13-16, 2015. p. 2974-2982. DOI : 10.1109/ICCV.2015.340.Geometry in Active Learning for Binary and Multi-class Image Segmentation, Ksenia Konyushkova, Raphael Sznitman, and Pascal Fua, submitted to PAMI, 2016.
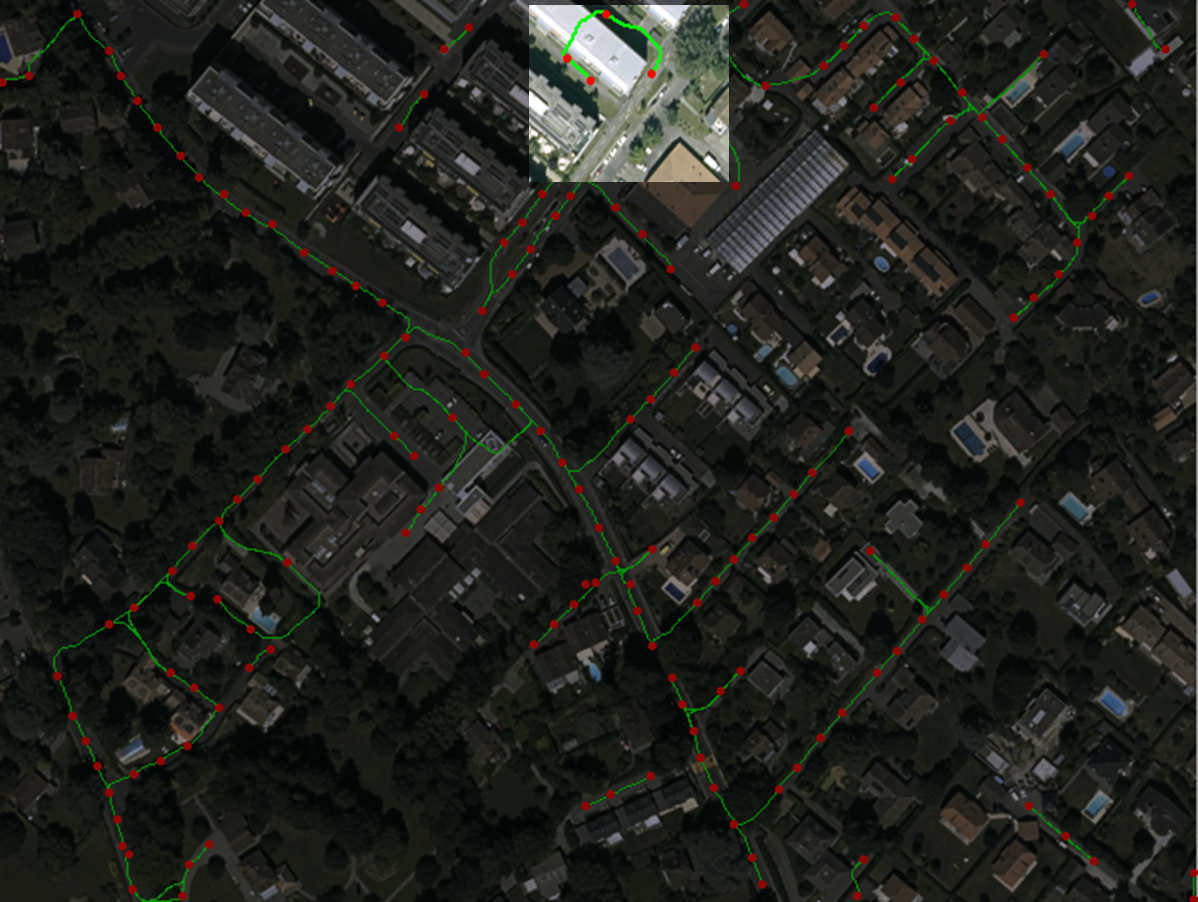
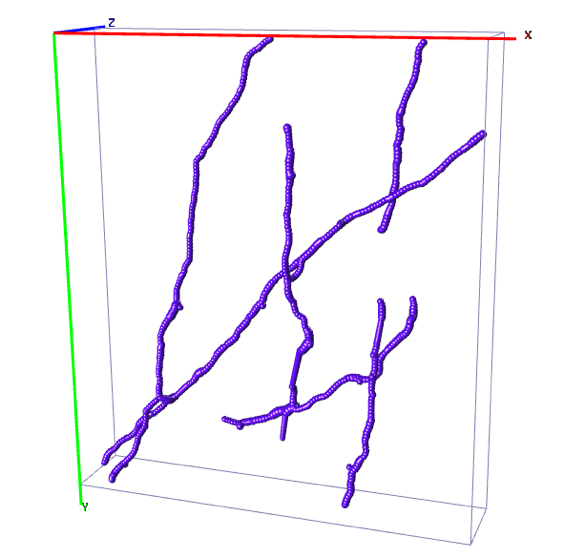
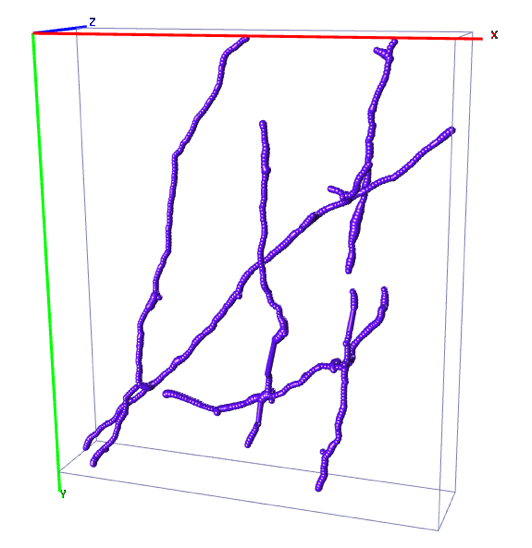
Reconstruction of Curvilinear Networks
It was shown that state-of-the-art delineation algorithms can greatly benefit from supervied Machine Learning methods. However, it requires a significant amount of labelled training data.
We propose an Active Learning method that takes advantage of the specificities of the delineation problem. Our approach operates on a graph and allows to reduce the annotation effort by up to 80%. It uses the assumption of the smoothness of data, predicting that the samples that stand out from their neighbourhood in image can be particularly ambiguous for a classifier.

References
Please note that the publication lists from Infoscience integrated into the EPFL website, lab or people pages are frozen following the launch of the new version of platform. The owners of these pages are invited to recreate their publication list from Infoscience. For any assistance, please consult the Infoscience help or contact support.