Learning to Fuse 2D and 3D Image Cues for Monocular Body Pose Estimation
Most recent approaches to monocular 3D human pose estimation rely on Deep Learning. They typically involve regressing from an image to either 3D joint coordinates directly or 2D joint locations from which 3D coordinates are inferred. Both approaches have their strengths and weaknesses and we therefore propose a novel architecture designed to deliver the best of both worlds by performing both simultaneously and fusing the information along the way. At the heart of our framework is a trainable fusion scheme that learns how to fuse the information optimally instead of being hand-designed. This yields significant improvements upon the state-of-the-art on standard 3D human pose estimation benchmarks.
Results
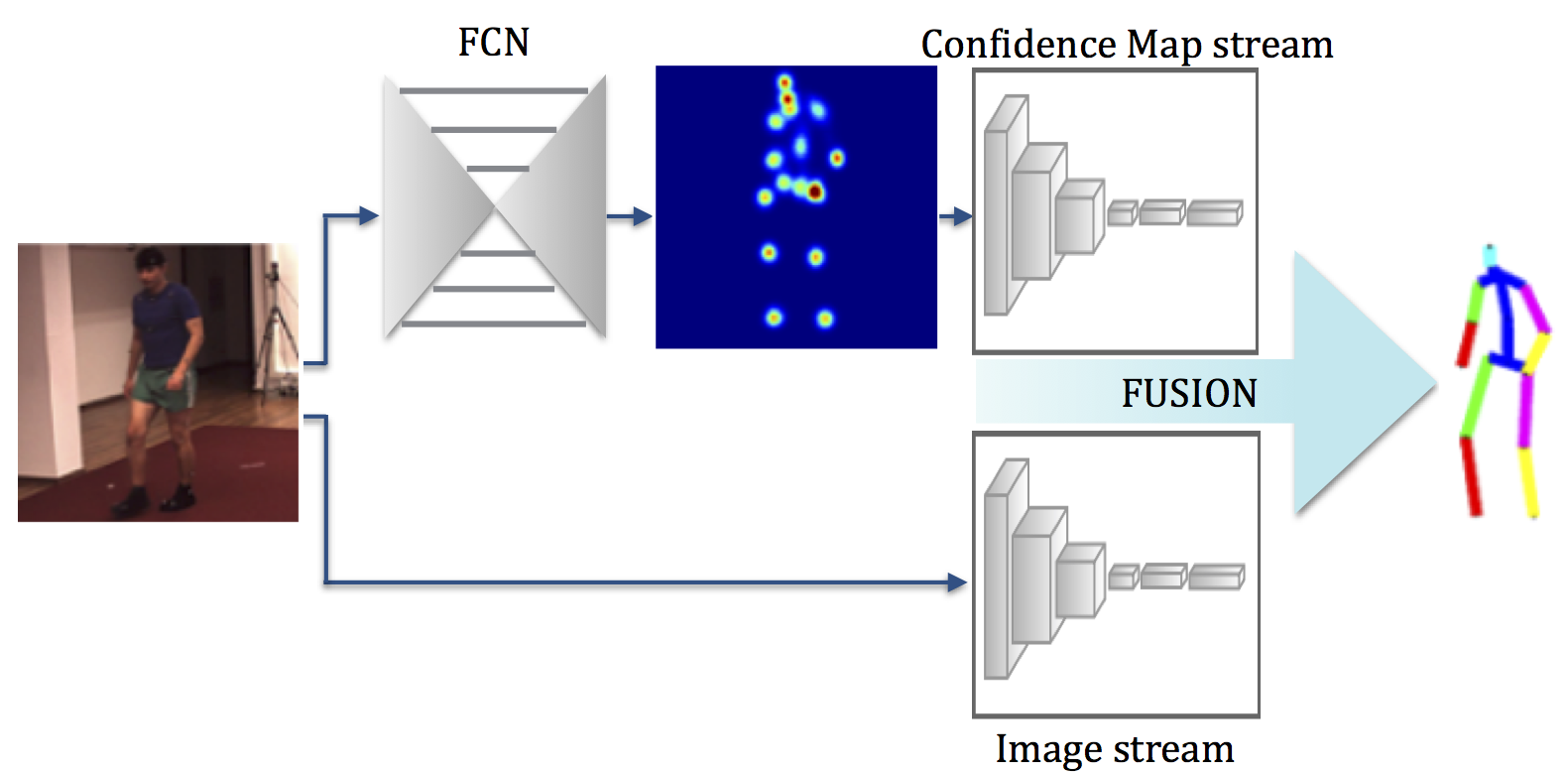
Embed of video is only possible from Mediaspace, Vimeo or Youtube
Embed of video is only possible from Mediaspace, Vimeo or Youtube
Embed of video is only possible from Mediaspace, Vimeo or Youtube
We further provide predictions from HumanEva-I sequences below.
Embed of video is only possible from Mediaspace, Vimeo or Youtube
Embed of video is only possible from Mediaspace, Vimeo or Youtube
We also demonstrate the performance of our approach on KTH Multiview Football II below.
Embed of video is only possible from Mediaspace, Vimeo or Youtube
Our code is available under the terms of the MIT license in the following link: [code].
Direct Prediction of 3D Body Poses from Motion Compensated Sequences
We propose an efficient approach to exploiting motion information from consecutive frames of a video sequence to recover the 3D pose of people. Previous approaches typically compute candidate poses in individual frames and then link them in a post-processing step to resolve ambiguities. By contrast, we directly regress from a spatio-temporal volume of bounding boxes to a 3D pose in the central frame.
We further show that, for this approach to achieve its full potential, it is essential to compensate for the motion in consecutive frames so that the subject remains centered. This then allows us to effectively overcome ambiguities and improve upon the state-of-the-art by a large margin on the Human3.6m, HumanEva, and KTH Multiview Football 3D human pose estimation benchmarks.
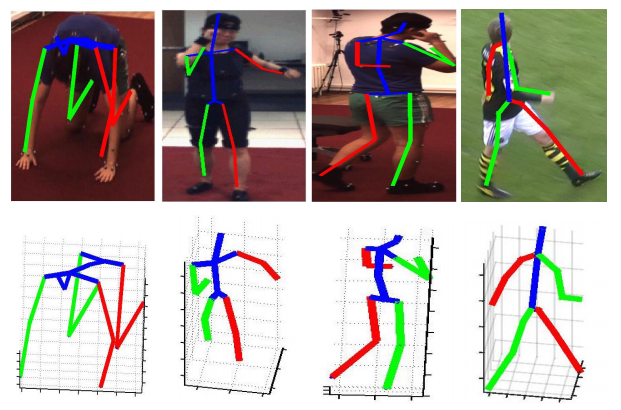
Results
Embed of video is only possible from Mediaspace, Vimeo or Youtube
Embed of video is only possible from Mediaspace, Vimeo or Youtube
Embed of video is only possible from Mediaspace, Vimeo or Youtube
We obtain RSTVs using our CNN-based motion compensation algorithm. The video below depicts several motion compensation examples on our datasets.
Embed of video is only possible from Mediaspace, Vimeo or Youtube
We provide examples of 3D human pose estimation with kernel ridge regression (KRR), kernel dependency estimation (KDE) and deep network (DN) regressors, applied on rectified spatiotemporal volumes (RSTVs). RSTV+DN yields more accurate 3D pose estimates.
Embed of video is only possible from Mediaspace, Vimeo or Youtube
We provide further visualization for the HumanEva dataset below.
Embed of video is only possible from Mediaspace, Vimeo or Youtube

The 3D body pose is recovered from the left camera view, and reprojected on the others. Our method can reliably recover the 3D pose and reprojects well on other camera views which were not used to compute the pose.
References
Learning to Fuse 2D and 3D Image Cues for Monocular Body Pose Estimation
2017. International Conference on Computer Vision (ICCV). p. 3961-3970. DOI : 10.1109/ICCV.2017.425.Structured Prediction of 3D Human Pose with Deep Neural Networks
2016. British Machine Vision Conference (BMVC), York, UK, September 19-22, 2016. p. 130.1-130.11. DOI : 10.5244/C.30.130.Direct Prediction of 3D Body Poses from Motion Compensated Sequences
2016. Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, Nevada, USA, June 26-July 1, 2016. p. 991-1000. DOI : 10.1109/CVPR.2016.113.Contact
| Bugra Tekin | [email] |
| Mathieu Salzmann | [email] |
| Pascal Fua | [email] |