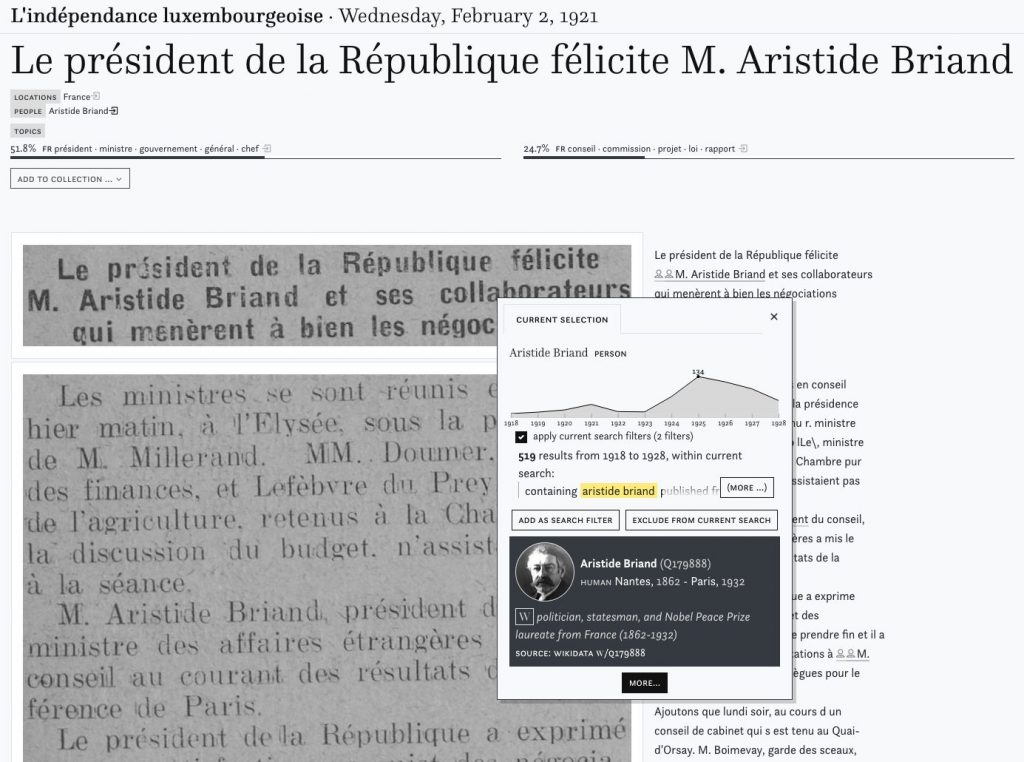
These datasets corresponds to several layers of semantic annotations (named entities, topics, OCR quality assessment, text reuse clusters, etc.) over the impresso historical newspaper corpora. They were created in the context of the impresso – Media Monitoring of the Past project, by the impresso team.
The release is about to be finalized, more information in Summer 2022!
Contact: Maud Ehrmann, Matteo Romanello, Simon Clematide (UZH)
Related publication:
Please note that the publication lists from Infoscience integrated into the EPFL website, lab or people pages are frozen following the launch of the new version of platform. The owners of these pages are invited to recreate their publication list from Infoscience. For any assistance, please consult the Infoscience help or contact support.
Language Resources for Historical Newspapers: the Impresso Collection
Following decades of massive digitization, an unprecedented amount of historical document facsimiles can now be retrieved and accessed via cultural heritage online portals. If this represents a huge step forward in terms of preservation and accessibility, the next fundamental challenge– and real promise of digitization– is to exploit the contents of these digital assets, and therefore to adapt and develop appropriate language technologies to search and retrieve information from this `Big Data of the Past’. Yet, the application of text processing tools on historical documents in general, and historical newspapers in particular, poses new challenges, and crucially requires appropriate language resources. In this context, this paper presents a collection of historical newspaper data sets composed of text and image resources, curated and published within the context of the `impresso – Media Monitoring of the Past’ project. With corpora, benchmarks, semantic annotations and language models in French, German and Luxembourgish covering ca. 200 years, the objective of the impresso resource collection is to contribute to historical language resources, and thereby strengthen the robustness of approaches to non-standard inputs and foster efficient processing of historical documents.
Proceedings of the 12th Language Resources and Evaluation Conference
2020-05-11
12th International Conference on Language Resources and Evaluation (LREC), Marseille, France, May 11-16 2020.p. 958-968
DOI : 10.5281/zenodo.4641902