Query Approximation
Modern analytical engines rely on Approximate Query Processing (AQP) to provide faster response times than the hardware allows for exact query answering. However, existing AQP methods impose steep performance penalties as workload unpredictability increases. Specifically, offline AQP relies on predictable workloads to create samples that match the queries in a priori to query execution, providing reductions in query response times when queries match the expected workload. As soon as workload predictability diminishes, existing online AQP methods create query-specific samples with little reuse across queries, producing significantly smaller gains in response times. As a result, existing approaches cannot fully exploit the benefits of sampling under increased unpredictability.
At DIAS we analyze sample creation and propose a framework for building, expanding, and merging samples to adapt to the changes in workload predicates. Our framework speeds up online sampling processing as a function of sample reuse, ranging from practically zero to full online sampling time and from 2.5x to 19.3x in a simulated exploratory workload.
Elastic & Distributed Query Engines
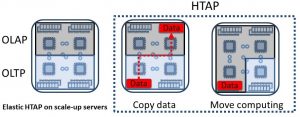
We build transactional and analytical engines that leverage native cloud functionality, such as elasticity and distribution. We provide fine-grained elasticity through cross-cutting system designs, spanning throughout the whole software virtualization stack, whereas we build our distributed query processing systems on top of Spark and other parallel frameworks.
Query Accelerators
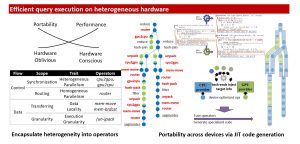
Traditionally, query engines are optimized for CPUs, but nowadays modern servers are becoming increasingly heterogeneous and equipped with multiple hardware accelerators, like GPUs. In this line of work, we investigate how different accelerators can be used by the query engine to increase its performance as well as provide isolation between queries. We design new hardware-conscious algorithms, study how existing ones perform across different micro-architectures and investigate multi-device query execution. Lastly, we provide engine designs that generalize device-specific approaches to achieve efficient heterogeneous-device execution through just-in-time code generation.