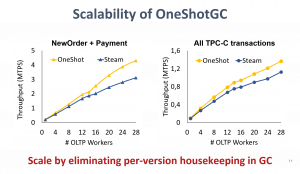
Most modern in-memory online transaction processing (OLTP) engines rely on multi-version concurrency control (MVCC) to provide data consistency guarantees in the presence of conflicting data accesses. MVCC improves concurrency by generating a new version of a record on every write, thus increasing the storage requirements. Existing approaches rely on garbage collection and chain consolidation to reduce the length of version chains and reclaim space by freeing unreachable versions. However, finding unreachable versions requires the traversal of long version chains, which incurs random accesses right into the critical path of transaction execution, hence limiting scalability.
Our research introduces OneShotGC, a new multi-version storage design that eliminates version traversal during garbage collection, with minimal discovery and memory management overheads. OneShotGC leverages the temporal correlations across versions to opportunistically cluster them into contiguous memory blocks that can be released in one shot. We implement OneShotGC in Proteus (add a link to Proteus https://proteusdb.com/ ) and use YCSB and TPC-C to experimentally evaluate its performance with respect to the state-of-the-art, where we observe an improvement of up to 2x in transactional throughput.
Computation
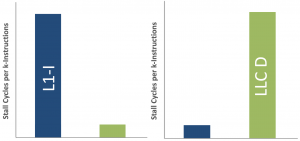
Micro-architectural behavior of traditional disk-based online transaction processing (OLTP) systems has been investigated extensively over the past couple of decades. Results show that traditional OLTP mostly under-utilize the available micro-architectural resources. In-memory OLTP systems, on the other hand, process all the data in mainmemory, and therefore, can omit the buffer pool. In addition, they usually adopt more lightweight concurrency control mechanisms, cache-conscious data structures, and cleaner codebases since they are usually designed from scratch. Hence, we expect significant differences in micro-architectural behavior when running OLTP on platforms optimized for inmemory processing as opposed to disk-based database systems. In particular, we expect that in-memory systems exploit micro architectural features such as instruction and data caches significantly better than disk-based systems.
This research sheds light on the micro-architectural behavior of in-memory database systems by analyzing and contrasting it to the behavior of disk-based systems when running OLTP workloads. The results show that despite all the design changes, in-memory OLTP exhibits very similar microarchitectural behavior to disk-based OLTP systems: more than half of the execution time goes to memory stalls where L1 instruction misses and the long-latency data misses from the last-level cache are the dominant factors in the overall stall time. Even though aggressive compilation optimizations can almost eliminate instruction misses, the reduction in instruction stalls amplifies the impact of last-level cache data misses. As a result, the number of instructions retired per cycle barely reaches one on machines that are able to retire up to four for both traditional disk-based and new generation in-memory OLTP.
Publications
Please note that the publication lists from Infoscience integrated into the EPFL website, lab or people pages are frozen following the launch of the new version of platform. The owners of these pages are invited to recreate their publication list from Infoscience. For any assistance, please consult the Infoscience help or contact support.
One-shot Garbage Collection for In-memory OLTP through Temporality-aware Version Storage
2023-05-01. p. 19. DOI : 10.1145/3588699.Please note that the publication lists from Infoscience integrated into the EPFL website, lab or people pages are frozen following the launch of the new version of platform. The owners of these pages are invited to recreate their publication list from Infoscience. For any assistance, please consult the Infoscience help or contact support.
Improving K-means Clustering Using Speculation
2023-08-01. Workshop on Applied AI for Database Systems and Applications (AIDB’23), Vancouver, Canada, August 28 – September 1, 2023.Please note that the publication lists from Infoscience integrated into the EPFL website, lab or people pages are frozen following the launch of the new version of platform. The owners of these pages are invited to recreate their publication list from Infoscience. For any assistance, please consult the Infoscience help or contact support.
Micro-architectural analysis of in-memory OLTP: Revisited
The VLDB Journal. 2021-03-31. Vol. 30, p. 641–665. DOI : 10.1007/s00778-021-00663-8.Micro-architectural Analysis of Database Workloads
Lausanne, EPFL, 2021.Micro-architectural Analysis of OLAP: Limitations and Opportunities
Proceedings Of The Vldb Endowment. 2020-02-01. Vol. 13, num. 6, p. 840-853. DOI : 10.14778/3380750.3380755.Micro-architectural Analysis of In-memory OLTP
2016. SIGMOD 2016. p. 387-402. DOI : 10.1145/2882903.2882916.ADDICT: Advanced Instruction Chasing for Transactions
2014. 41st International Conference on Very Large Databases, Waikoloa, Hawaii, USA, August 31 – September 4, 2015. p. 1893–1904. DOI : 10.14778/2733085.2733095.OLTP in Wonderland — Where do cache misses come from in major OLTP components?
2013. 9th International Workshop on Data Management on New Hardware, New York, New York, USA, June 24, 2013. p. 8:1–8:6. DOI : 10.1145/2485278.2485286.Please note that the publication lists from Infoscience integrated into the EPFL website, lab or people pages are frozen following the launch of the new version of platform. The owners of these pages are invited to recreate their publication list from Infoscience. For any assistance, please consult the Infoscience help or contact support.
A Methodology for OLTP Micro-architectural Analysis
2017-05-14. DAMON, Chicago, Illinois, May, 14 – 19, 2017. p. 1. DOI : 10.1145/3076113.3076116.
Storage
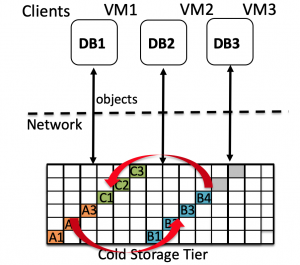
Enterprise databases use storage tiering to lower capital and operational expenses. In such a setting, data waterfalls from an SSD-based high-performance tier when it is “hot” (frequently accessed) to a disk-based capacity tier and finally to a tape-based archival tier when “cold” (rarely accessed). To address the unprecedented growth in the amount of cold data, hardware vendors introduced new devices named Cold Storage Devices (CSD) explicitly targeted at cold data workloads. With access latencies in tens of seconds and cost/GB as low as $0.01/GB/month, CSD provide a middle ground between the low-latency (ms), high-cost, HDD-based capacity tier, and high-latency (min to h), low-cost, tape-based, archival tier.
In this research, we examine the use of CSD as a replacement for both capacity and archival tiers of enterprise databases. While CSD offer major cost savings, current database systems can suffer from severe performance drop when CSD are used as a replacement for HDD due to the mismatch between design assumptions made by the query execution engine and actual storage characteristics of the CSD. We build a CSD-driven query execution framework, called Skipper, that modifies both the database execution engine and CSD scheduling to be able to benefit both from the low cost of CSD without sacrificing its high latency cost. Results show that our implementation of the architecture based on PostgreSQL and OpenStack Swift, is capable of completely masking the high latency overhead of CSD, thereby opening up CSD for wider adoption as a storage tier for cheap data analytics over cold data.
Publications
Please note that the publication lists from Infoscience integrated into the EPFL website, lab or people pages are frozen following the launch of the new version of platform. The owners of these pages are invited to recreate their publication list from Infoscience. For any assistance, please consult the Infoscience help or contact support.