Cloud computing offers its users centralized and inexpensive computing services through the integration of hardware and middleware into a complete computing stack, thereby facilitating the development of large and scalable applications. Clouds also run applications efficiently and inexpensively, by leveraging the technical expertise of cloud computing providers and by enabling a significant reduction in energy consumption, since computing resources can be better utilized across users. This reduction of IT costs is motivating Swiss companies to invest considerably in cloud computing.
There were still however problems of trust from many of the user communities towards the concept. Our project has succeeded to build a prototype of a Cloud storage system which is trustworthy and will expand the use of Cloud computing to even the most reluctant and demanding users.
System Architecture
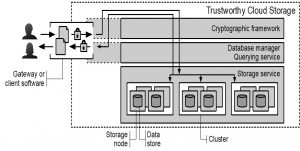
From a high-level perspective, the TCS system comprises of a collection of components shown in Figure 1. First, at the lowest level, local data stores securely maintain data on individual nodes of the system. The data store may need to use a specialized database and/or file-system with a dedicated mechanism for trustworthiness.
Second, a distributed data store aggregates the local stores to implement a scalable, robust, and highly available cloud storage service. Individual nodes are gathered in clusters to support large data sets and many concurrent clients. In turn, several clusters can be connected with each other to support fault-tolerance and high-availability (by replicating data in distinct locations), as well as provide geographical control over the data. Interactions between nodes and clusters are managed by distributed protocols ensuring consistent operations on the data.
Third, data querying facilities allow users to access data in non-trivial ways. Throughout this project, our work focused on providing robust performance regardless of the underlying data inputs and the underlying storage infrastructure. We, therefore, specified the architecture of a novel query engine that can be used for in-situ querying of heterogeneous data sources. We also identified two very diverse recent storage trends, i.e., cold storage devices and main memory storage, and proposed techniques that incorporate them in the data management system stack.
Finally, a cryptographic framework implements the various facets of trustworthiness by the means of cryptographic algorithms. Some critical operations, such as encryption of the data, are performed by the user or a trusted gateway, while others take place at individual storage nodes or in other components of the framework (e.g., database manager).
This work has been funded by the Swiss National Science Foundation (SNSF), project No. CRSII1 136318/1.
Project Partners
Anastasia Ailamaki, EPFL (Principal Investigator)
Pascal Felber, Université de Neuchâtel
Publications
Please note that the publication lists from Infoscience integrated into the EPFL website, lab or people pages are frozen following the launch of the new version of platform. The owners of these pages are invited to recreate their publication list from Infoscience. For any assistance, please consult the Infoscience help or contact support.
Adaptive Query Processing on RAW Data
2014. 40th International Conference on Very Large Databases, Hangzhou, China, September 1-5, 2014.Please note that the publication lists from Infoscience integrated into the EPFL website, lab or people pages are frozen following the launch of the new version of platform. The owners of these pages are invited to recreate their publication list from Infoscience. For any assistance, please consult the Infoscience help or contact support.
Just-In-Time Data Virtualization: Lightweight Data Management with ViDa
2015. 7th Biennial Conference on Innovative Data Systems Research (CIDR), Asilomar, California, USA, January 4-7, 2015.Please note that the publication lists from Infoscience integrated into the EPFL website, lab or people pages are frozen following the launch of the new version of platform. The owners of these pages are invited to recreate their publication list from Infoscience. For any assistance, please consult the Infoscience help or contact support.
NoDB in Action: Adaptive Query Processing on Raw Data
2012. The 38th International Conference on Very Large Data Bases, Istanbul, Turkey, August 27-31, 2012. p. 1942–1945. DOI : 10.14778/2367502.2367543.Please note that the publication lists from Infoscience integrated into the EPFL website, lab or people pages are frozen following the launch of the new version of platform. The owners of these pages are invited to recreate their publication list from Infoscience. For any assistance, please consult the Infoscience help or contact support.