Research Projects are open to EPFL students.
Arrangements of lenslets can be used to create document security features. The goal is to create a flexible program that can create surface representations (meshes) of such arrangements according to the specification of the user. Such lenslet mesh descriptions can be entered into the Blender software. This software provides simulations of the interaction between the arrangement of lenslets and the selected light sources.
Deliverables: Report and running prototype (Matlab). Blender lenslet simulations.
Prerequisites:
– knowledge of image processing / computer vision
– basic coding skills in Matlab
Level: BS or MS semester project
Supervisors:
Prof. Roger D. Hersch, BC110, rd.hersch@epfl.ch, cell: 077 406 27
Dr Romain Rossier, Innoview Sàrl, romain.rossier@innoview.ch, , tel 078 664 36 44
Description:
Recent development of Large Language Models (LLMs) makes it easier to generate desired text by users [1]. Despite the success and convinence it brings, there is also an urgent worry about the potential negative impacts that LLMs could cause on social public, such as fake news, plagiarism, biasd information and other social security issues[2].
In this project, we aim to analyze the difference of LLMs-generated text with human written text, and further explore how to detect them by designing machine learning or deep learning models. If you are interested in this project, here are a few existing references to explore: [3,4].
Key Question:
1. The difference of LLMs-generated text and human written text, from the perspective of both human-understanding and statistic/latent analysis.
2. Can we use or design machine learning or deep learning methods to distinguish them effectively? And further evaluate the detectors’ generalization and robustness.
References:
[1] Solaiman, Irene, et al. “Release strategies and the social impacts of language models.” arXiv preprint arXiv:1908.09203 (2019).
[2] Weidinger, Laura, et al. “Ethical and social risks of harm from language models.” arXiv preprint arXiv:2112.04359 (2021).
[3] Guo, Biyang, et al. “How close is chatgpt to human experts? comparison corpus, evaluation, and detection.” arXiv preprint arXiv:2301.07597 (2023).
[4] Mitchell, Eric, et al. “Detectgpt: Zero-shot machine-generated text detection using probability curvature.” arXiv preprint arXiv:2301.11305 (2023).
Deliverables:
Code, well cleaned up and easily reproducible.
Written Report, including explaining for the models, steps taken for the project and the performance of models.
Prerequisites:
Python and Pytorch.
Level:
MS Level: semester project.
Supervisor:
Daichi Zhang (daichi.zhang@epfl.ch)
Description:
The rapid development of generative models has brought great changes in our daily life, such as large language models, diffusion models and even vision foundation models. However, are those models always safe enough to use? Will they cause harm to users, such as data leakage [1,2], generating biased results [3], or simply attacked or manipulated by attackers [4]?
In this project, we are interested in the safety problems of current generative models and aim to evaluate how vulnerable they are.
Key Question:
-
Data Leakage: since the generatve models could access to large-scale training data as well as the user input data, will it cause data leakage when genereating results?
-
Biased Results: will the generated results be fair enough or just a biased view of trained generative models.
-
Attack by users: can we perturbate or attack target generative models to make it generating wrong or desired manipulated results?
References:
[1] Somepalli, Gowthami, et al. “Diffusion art or digital forgery? investigating data replication in diffusion models.” Proceedings of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition. 2023.
[2] Carlini, Nicholas, et al. “Extracting training data from large language models.” 30th USENIX Security Symposium (USENIX Security 21). 2021.
[3] Luccioni, Alexandra Sasha, et al. “Stable bias: Analyzing societal representations in diffusion models.” arXiv preprint arXiv:2303.11408 (2023).
[4] Perez, Fábio, and Ian Ribeiro. “Ignore previous prompt: Attack techniques for language models.” arXiv preprint arXiv:2211.09527 (2022).
Deliverables:
Code, well cleaned up and easily reproducible.
Written Report, including details of investigated models, steps taken for the evaluation and the evaluation results.
Prerequisites:
Python and Pytorch.
Level:
BS or MS semester project.
Supervisor:
Daichi Zhang (daichi.zhang@epfl.ch)
Image-based rendering can date back to the 1990s. Unlike traditional Computer Graphics rendering, which requires explicit scene geometry and scene texture, image-based rendering renders a scene based on observations of the scene, i.e., photographs taken in the real/synthesised scene.
Given an image collection of a scene under different viewing directions, the method of NeRF can faithfully synthesise novel views that are 3D-consistent. However, it is still an open question of how to render the scene under a novel lighting condition.
There are a few works about relighting a NeRF-like implicit scene representation. There are two steps for this process: scene decomposition and 3D scene extraction from the decomposition. Afterwards, we can relight the 3D representation easily. A common material model assumed for all objects of interests is the Disney BSDF model. However, there are a variety of other materials such as glass or glints that cannot be adequately represented by this assumption.
In this project, we work with a dedicated type of surface appearance and explore various 3D scene representations, either implicit or explicit, and develop corresponding scene decomposition strategies which would then enable scene novel view inquires and relighting.
Type of work
- MS Level: semester project / master project ** can be adapted to bachelor project in case of a capable bachelor student.
- 60% research, 40% development
Prerequisite:
- Knowledge in deep learning frameworks (e.g., PyTorch or Tensorflow), image processing and Computer Vision.
- Experience with 3D vision is required.
- Knowledge with Computer Graphics is recommended.
Supervisor:
- Dongqing Wang, dongqing.wang@epfl.ch
Reference Literature:
- NeRF: Neural Radiance Field https://www.matthewtancik.com/nerf
- NeRV: Neural Reflectance and Visibility Fields for Relighting and View Synthesis https://pratulsrinivasan.github.io/nerv/
- Neural Radiance Fields for Outdoor Scene Relighting https://4dqv.mpi-inf.mpg.de/NeRF-OSR/
- NeRFactor: Neural Factorization of Shape and Reflectance Under an Unknown Illumination https://arxiv.org/abs/2106.01970
Some types of moiré patterns rely on grayscale images. These moiré patterns can be used for the prevention of counterfeits. The present project aims at creating a grayscale image editor. Designers should be able to shape their grayscale image by various means (interpolation between spatially defined grayscale values, geometric transformations, image warping, etc…).
Deliverables: Report and running prototype (Matlab).
Prerequisites:
– knowledge of image processing / computer vision
– basic coding skills in Matlab
Level: BS or MS semester project
Supervisors:
Dr Romain Rossier, Innoview Sàrl, romain.rossier@innoview.ch, , tel 078 664 36 44
Prof. Roger D. Hersch, BC110, rd.hersch@epfl.ch, cell: 077 406 27 09
3D objects created with DreamFusion taking prompts. (DreamFusion, Ben Poole et al.) This project will be in this line of work and aims to improve the quality of generated 3D contents.
Description
In recent years, a novel class of generative models known as Diffusion Models (DMs) has emerged. These models define a forward process that introduces a small amount of Gaussian noise into data samples, and a learnable reverse process (generation process) that gradually removes the noise. When applied to natural images, this modeling approach has been shown to outperform state-of-the-art Generative Adversarial Nets (GANs).
Though 2D images are natural for screens and printing, it would be nice if we could generate 3D content that can be seen from different views. However, collecting 3D data is tedious, unlike 2D photos that can be captured daily using smartphones and naive scaling 2D models to 3D is usually computationally infeasible.
In this project, we will use 2D image supervision for 3D content creation. We will guide 3D content creation with several 2D supervision, through several methods, such as rasterization, and volume rendering.
- Stable diffusion: https://github.com/Stability-AI/stablediffusion
- 3D content: https://dreamfusion3d.github.io/
Deliverables
- Code, well cleaned up and easily reproducible.
- Written Report, explaining the literature and steps taken for the project.
Prerequisites
- Python and PyTorch.
- Experience with Deep Learning methods and Convolutional Networks
- (required) publication record or research project experience in generative research or 3D modeling.
Level: Master Student
- Supervisor: Yufan Ren (website), Email: yufan.ren@epfl.ch
Startup company Innoview Sàrl has developed software to recover a message hidden into patterns. Appropriate settings of parameters enable the detection of counterfeits. The goal of the project is to define optimal parameters for different sets of printing conditions (resolution, type of paper, type printing device, complexity of hidden watermark, etc..). The project involves tests on a large data set and appropriate statistics.
Deliverables: Report and running prototype (Android, Matlab).
Prerequisites:
– knowledge of image processing / computer vision
– basic coding skills in Matlab and/or Java Android
Level: BS or MS semester project
Supervisors:
Dr Romain Rossier, Innoview Sàrl, romain.rossier@innoview.ch, , tel 078 664 36 44
Prof. Roger D. Hersch, BC110, rd.hersch@epfl.ch, cell: 077 406 27 09
Description:
The project aims to explore the potential advantages of employing 2D Gaussian Splatting as a technique for image representation and compression.
3D Gaussian Splatting [1] is a recent technique used to represent a scene by 3D Gaussians from a set of photos taken from different angles.
2D Gaussian Splatting [2], akin to its 3D counterpart, aims to represent images as a collection of 2D Gaussians, by optimizing their shapes, transparencies, positions, and colors. In comparison, other techniques such as DiffVG [3] or LIVE [4] focus on optimizing coordinates and colors of vector objects such as polygons and Bezier closed shapes, which is more delicate due to the non-differentiability of rasterized pixel values.
Key Questions:
Optimization Efficiency: Is 2D Gaussian Splatting [2] a faster and more stable approach to represent an image than DiffVG [3] and LIVE [4], especially considering the complexities of optimizing vector objects?
Image Quality: Given a fixed number of parameters (2D Gaussian parameters for instance) or a specific compression ratio, which method yields superior image quality – 2D Gaussian Splatting [2] or vector object-based techniques like DiffVG [3] and LIVE [4]?
Text-to-2DGaussians: Recent work like VectorFusion [5] leverages Diffusion models and score distillation sampling (SDS, [6]) to generate SVG images (vector objects) from text. Can we adapt them to use 2D Gaussians in place of vector objects?
Tasks:
Comparative Analysis: Evaluate and compare 2D Gaussian Splatting with DiffVG and LIVE in terms of optimization time, reconstruction quality, training stability, and other relevant performance metrics.
Compression Algorithm Design: Design some algorithm to use such methods for image compression. Compare the different methods.
Text-to-2DGaussians: Implement an algorithm to perform Text-to-2DGaussians using SDS loss (or similar) as optimization objective. Assess the feasibility and quality of the technique.
References:
[1] Kerbl, Bernhard, et al. “3d gaussian splatting for real-time radiance field rendering.” ACM Transactions on Graphics (ToG) 42.4 (2023): 1-14.
[2] https://github.com/OutofAi/2D-Gaussian-Splatting
[3] Li, Tzu-Mao, et al. “Differentiable vector graphics rasterization for editing and learning.” ACM Transactions on Graphics (TOG) 39.6 (2020): 1-15.
[4] LIVE: Ma, Xu, et al. “Towards layer-wise image vectorization.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[5] Jain, Ajay, Amber Xie, and Pieter Abbeel. “Vectorfusion: Text-to-svg by abstracting pixel-based diffusion models.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023
[6] Poole, Ben, et al. “Dreamfusion: Text-to-3d using 2d diffusion.” arXiv preprint arXiv:2209.14988 (2022).
Deliverables: Deliverables should include code, well cleaned up and easily reproducible, as well as a written report, explaining the models, the steps taken for the project and the performances of the models.
Prerequisites: Python and PyTorch.
Level: BS or MS research project
Number of students: 1
Supervisor: Martin Nicolas Everaert (martin.everaert [at] epfl.ch)
Introduction
Computed Tomography (CT) images are particularly helpful for medical diagnosis of multiple diseases, especially for brain lesions analysis. While High-Dose CT images are easy to interpret thanks to their sharp contrast, the chemical product and the X-rays radiation used to enhance the contrast is invasive and toxic for the patient. In that regard, most CT imaging techniques are performed with low-dose. This implies that the resulting image is less contrasted and that the signal to noise ratio is much higher[1].
In that regard, CT image denoising is a crucial step to visualize and analyze such images. Most classic image processing algorithms have been transferred to the medical image domain, producing satisfactory results [1]. The results have been boosted by a large margin by the introduction of neural nets for image restoration. [2,3]
However, one key limitation for the interpretability of the produced method is that neural networks hallucinate patterns and textures they have seen in the training set. Therefore, these methods are not really trustworthy for radiologists.
In order to leverage the expressive power and denoising capacity of deep neural networks without recreating patterns which have been seen during training, the idea is to train on synthetic abstract images which do not directly contain the patterns observed in real CT images. That way, our network won’t be biased to reproduce expected patterns, while maintaining good performances.
Tasks
In this semester project , we will try to :
- create a database of abstract dead leaves images mimicking the statistics of real images [4,5]
- study the noise distribution of real CT images by using a real dataset of noisy images
- train a denoising network with the simulated ground truth and noisy images
- quantify the hallucinations made by the network trained on real images vs simulated images [6]
- establish a test protocol for our network
Deliverables
Deliverables should include code, well cleaned up and easily reproducible, as well as a written report, explaining the models, the steps taken for the project and the performances of the models.
Prerequisites: Python and PyTorch, basics of image processing
Level: MS research project
Number of students: 1
References :
- A review on CT image noise and its denoising, 2018, Manoj Diwakara, Manoj Kumarb
- Low-Dose CT Image Denoising Using a Generative Adversarial Network With a Hybrid Loss Function for Noise Learning, 2020, YINJIN MA et al
- Investigation of Low-Dose CT Image Denoising Using Unpaired Deep Learning Methods, 2021, Zeheng Li, Shiwei Zhou, Junzhou Huang, Lifeng Yu, and Mingwu Jin
- Occlusion Models for Natural Images: A Statistical Study of a Scale-Invariant Dead Leaves Model, 2001, Ann B. Lee, David Mumford, Jinggang Huang
- Synthetic images as a regularity prior for image restoration neural networks, 2021, Raphael Achddou, Yann Gousseau, Said Ladjal
- Image Denoising with Control over Deep Network Hallucination, 2022, Qiyuan Liang, Florian Cassayre, Haley Owsianko, Majed El Helou, Sabine Süsstrunk
Contact: Raphaël Achddou, raphael.achddou@epfl.ch
- Use of different voices for different characters
- Automated understanding of the emotions suggested by a given part of the dialogues
- Adaptation of the generated audio to the emotions found (e.g. emphasis, speaking rate, pitch, volume)
- Coding skills in Python
- Experience or Interest in Text-to-Speech Models
Description
Single-Image super-resolution is the task of increasing an image resolution by inferring the missing high frequencies of an image. For this task, neural networks are commonly learnt on large natural images datasets [1, 2]. While these models produce impressive results on natural images, they fail to generalize to other unseen domains, such as drone images. To tackle this issue, [3] proposed DSR, a drone super-resolution dataset along with a baseline network. Each scene is acquired at multiple heights with two focal lengths (telecamera : the ground truth HR/ normal : the LR image)on two different cameras. While the initial paper has shown some interesting results, especially about exploiting the height as a conditioning of the SR, there is still a lot of room for improvement.
In this semester project, we will work on possible ways to better leverage the acquired dataset. Possible perspectives of improvement regard 1/ the domain gap between the two cameras, for which we may train a Camera-2-Camera mapping in the RAW color space[4,5] 2/ better exploiting images at different height to improve the current results 3/ Propose new architectures, such as diffusion models for super-resolution [6] 4/ Work on a lightweight distillation of the model that could work real time on the Drone.
References
[1] SwinIR: Image Restoration Using Swin Transformer, 2021
[2] Zoom To Learn, Learn To Zoom, 2019
[3] DSR Towards Drone Image Super-Resolution, 2022
[4] Cross-camera convolutional color constancy 2021
[5] Semi-Supervised Raw-to-Raw Mapping, 2021
[6] Image Super-Resolution via Iterative Refinement, 2021
Deliverables
Project report and reproducible code.
Prerequisites
Experience with Python, Pytorch, preferably some expertise in Image processing and machine learning.
Level
MS semester project
Type of Work
60 % research 40 % implementation
Supervisors
Raphael Achddou (raphael.achddou@epfl.ch)
Majed El Helou ( majed.elhelou@inf.ethz.ch)
Andreas Aakerberg (anaa@create.aau.dk)
Learned Neural Radiance Field as scene representation showing nice geometry reconstruction but requires >30 images. (NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis, Ben Mildenhall et al. )

Generalizable neural representation works with as few as three input views using generalizable priors. (SparseNeuS: Fast Generalizable Neural Surface Reconstruction from Sparse Views, Long et al.) This project would be in this research line and aims to improve further.
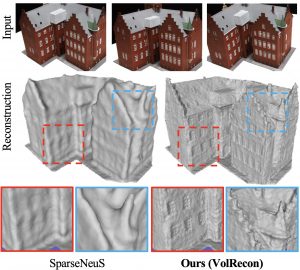
Our previous work in this line of research. Aims at achieving finer details. Will be presented on CVPR’23.
Description :
Neural Rendering is a branch of rendering technique that replaces one or more parts of the rendering pipeline with neural networks. The inductive bias of neural networks has been proven helpful in many Neural Rendering tasks, such as novel view synthesis (NeRF), surface reconstruction (volSDF), and material acquisition (NeRD).
In this project, we are interested in the generalization ability of Neural Rendering, e.g., given a set of images, infer novel views directly. There are several benefits of using generalizable features. Firstly, we skip the long training procedure with a fast-forward inference. Secondly, learnable features are beneficial in sparse input cases. Thirdly, the framework enables further optimization to improve quality.
We will build a generalizable rendering model based on existing network designs such as IBRNet and MVSNet, and train using pixel loss, depth loss, and patching warping loss.
Level
MS Level: semester project (senior) /master project
Prerequisite:
- Knowledge in deep learning frameworks (e.g., PyTorch), image processing, and Computer Vision.
- (required) publication record or research project experience in Differentiable rendering or neural rendering.
Supervisors:
- Yufan Ren (website), Email: yufan.ren@epfl.ch
Type of work:
50% research, 50% development
References:
[1] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
Introduction:
Recent work on text to 2D models such as Stable Diffusion trained on billions of text-image pairs have achieved stunning image synthesis quality. However, the model requires large scale datasets and industrial sized training models, a process that can be hard to be taken to 3D scenes generation.
To deal with this problem DreamFusion as the first work taking Diffusion models to 3D generation with facilitation of NeRF is able to accelerate this process and create view-consistent scene objects with mesh models for generalised forward rendering pipeline. See https://dreamfusion3d.github.io/ for a collection of generated results.
This project will focus on text-driven 3D content generation, looking at possibilities of exploiting pretrained 2D diffusion models or other similar architecture with 3D vision as priors to accomplish the following tasks 1. Create larger scaled scenes with realistic environment surroundings; 2. Generate specific materials with particular viewing effects that require 3D understanding of scene intrinsics such as transparent objects; 3. Editable texture / stylization for scene meshes controlled via text-input . We will be looking at CLIP and diffusion based models. A work close to this project can be found in Text2Mesh in the reference section.
Type of Work:
- MS Level: semester project / master project
- 60% research, 40% development
Supervisor:
- Dongqing Wang, dongqing.wang@epfl.ch
Prerequisite:
- Have taken a Machine Learning course and a Computer Vision course.
- Have sufficient Pytorch knowledge.
- Students will be working extensively with 3D scene generation and possibly editing, therefore prior experience with 3D vision and / or computer graphics knowledge will be a plus.
- Experience with diffusion models and / or CLIP will be a plus.
Reference Literature:
- Poole, Ben, et al. “Dreamfusion: Text-to-3d using 2d diffusion.” arXiv preprint arXiv:2209.14988 (2022).
- Chen, Yongwei, et al. “TANGO: Text-driven Photorealistic and Robust 3D Stylization via Lighting Decomposition.” arXiv preprint arXiv:2210.11277 (2022).
- Rombach, Robin, et al. “High-resolution image synthesis with latent diffusion models.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
- Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” International Conference on Machine Learning. PMLR, 2021.
- Michel, Oscar, et al. “Text2mesh: Text-driven neural stylization for meshes.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
- Haque, Ayaan, et al. “Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions.”arXiv preprint arXiv:2303.12789(2023).
- https://github.com/ashawkey/stable-dreamfusion
- https://github.com/CompVis/stable-diffusion
Description:
Recent research shows that existing large language models (trained on text data only) seem to be good at recognizing patterns from general sequences, extending beyond textual data to include arbitrary tokens [1, 2]. Images can also be represented by tokens (e.g. pixel values), and it seems that LLMs can perform some tasks like image denoising and completion [1, Figure 8], despite not being trained on images but on text data only.
Key Question:
The central question driving this project is whether LLMs, which have proven effective at denoising simple patterns [1, Figure 8], can be used to generate images from scratch through an iterative denoising process, akin to diffusion models [3].
Can we employ the sampling algorithm employed by diffusion models [3] without the need for UNet training, replacing it with queries to an LLM?
References:
[1] Mirchandani, Suvir, et al. “Large language models as general pattern machines.” arXiv preprint arXiv:2307.04721 (2023).
[2] https://slideslive.com/39006507/interactive-learning-in-the-era-of-large-models 19:35
[3] Ho, Jonathan, Ajay Jain, and Pieter Abbeel. “Denoising diffusion probabilistic models.” Advances in neural information processing systems 33 (2020): 6840-6851.
Deliverables: Deliverables should include code, well cleaned up and easily reproducible, as well as a written report, explaining the models, the steps taken for the project and the performances of the models.
Prerequisites: Python and PyTorch.
Level: MS research project
Number of students: 1
Supervisor: Martin Nicolas Everaert (martin.everaert [at] epfl.ch)