Abstract
Please note that the publication lists from Infoscience integrated into the EPFL website, lab or people pages are frozen following the launch of the new version of platform. The owners of these pages are invited to recreate their publication list from Infoscience. For any assistance, please consult the Infoscience help or contact support.
Saliency Detection Using Regression Trees on Hierarchical Image Segments
The currently best performing state-of-the-art saliency detection algorithms incorporate heuristic functions to evaluate saliency. They require parameter tuning, and the relationship between the parameter value and visual saliency is often not well understood. Instead of using parametric methods we follow a ma- chine learning approach, which is parameter free, to estimate saliency. Our method learns data-driven saliency-estimation functions and exploits the contributions of visual properties on saliency. First, we over-segment the image into superpixels and iteratively connect them to form hierarchical image segments. Second, from these segments, we extract biologically- plausible visual features. Finally, we use regression trees to learn the relationship between the feature values and visual saliency. We show that our algorithm outperforms the most recent state-of-the-art methods on three public databases.
Proceedings of the 21st IEEE International Conference on Image Processing
2014
21st IEEE International Conference on Image Processing, Paris, France, October 27-30, 2014.p. 3302-3306
DOI : 10.1109/ICIP.2014.7025668
The Code
Our source code can be found in the following file: HR
In order to run our code, you need to download three additional frameworks:
- A modified version of our SLIC superpixel extraction: Modified SLIC. You can find more information for the original work in this page.
After extracting the zip file, you need to execute the following code in MATLAB command window (when in the same directory)mex getSuperpixels.cpp SLIC.cpp
Radhakrishna Achanta, Appu Shaji, Kevin Smith, Aurelien Lucchi, Pascal Fua, and Sabine Süsstrunk, SLIC Superpixels Compared to State-of-the-art Superpixel Methods, IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 34, num. 11, p. 2274 – 2282, May 2012. - Gradient boosting tree implementation
R. Sznitman, C. Becker, F. Fleuret and P. Fua. Fast Object Detection with Entropy-Driven Evaluation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, Oregon, June 23-28, 2013. - Undirected Graphical Models (UGM) implementation
M. Schmidt, K. Murphy, G. Fung, and R. Rosales, Structure learning in random fields for heart motion ab- normality detection in Proceedings of the IEEE CVPR, 2008, pp. 1–8.
Our Saliency Maps
You can find the saliency maps that are generated by our method in the links below:
Contradicting Saliency Rules
The most recent and best-performing low-level saliency detection algorithms evaluate the final saliency by combining biologically-plausible color contrast features. However, their performances depend highly on the heuristic function selection and the tuned parameters, because these features do not always imply saliency, and the relationship between the parameter values and saliency is not always straightforward. For example, in Figure 1(a), we should not penalize border pixels, because the salient object touches the image boundary. However, in Figure 1(b), non-salient sky pixels have high contrast with the rest of the image, and should be penalized. These handcrafted rules, as in this case, can contradict each other and can lead us to inaccurate saliency estimations.
 |
 |
| (a) | (b) |
 |
 |
| (c) | (d) |
Figure 1: Image examples requiring contradicting saliency rules, and outputs of our saliency method.
Hierarchical Representation
We over-segment an input image into superpixels. These superpixels are then iteratively merged into larger segments. After all possible superpixel pairs are merged, their properties are updated and the method moves onto the next level. The algorithm stops if there is nothing left to merge. The merging method is simple and non-parametric, yet it generates an accurate hierarchical representation of the input image.

Figure 2: Hierarchical representation of an image (red lines indicate superpixel borders)
Visual Features
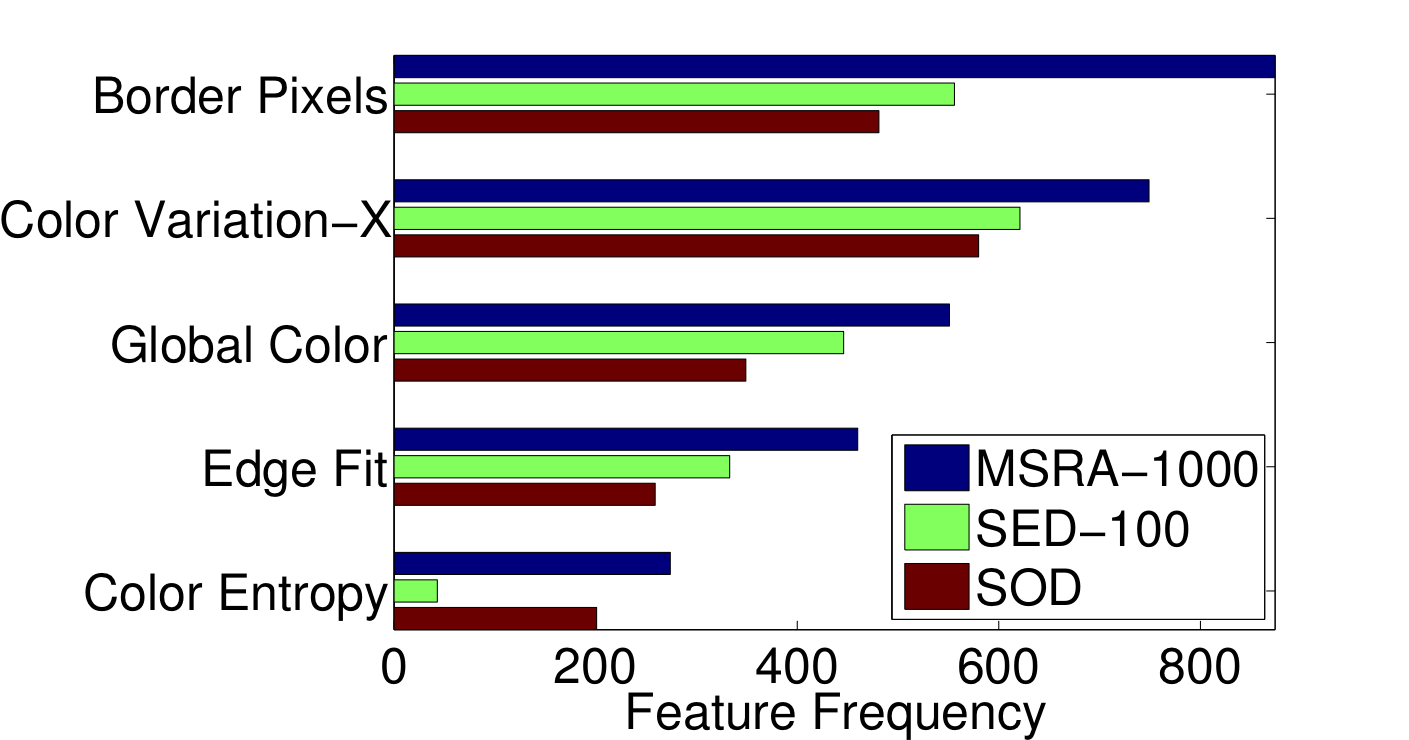
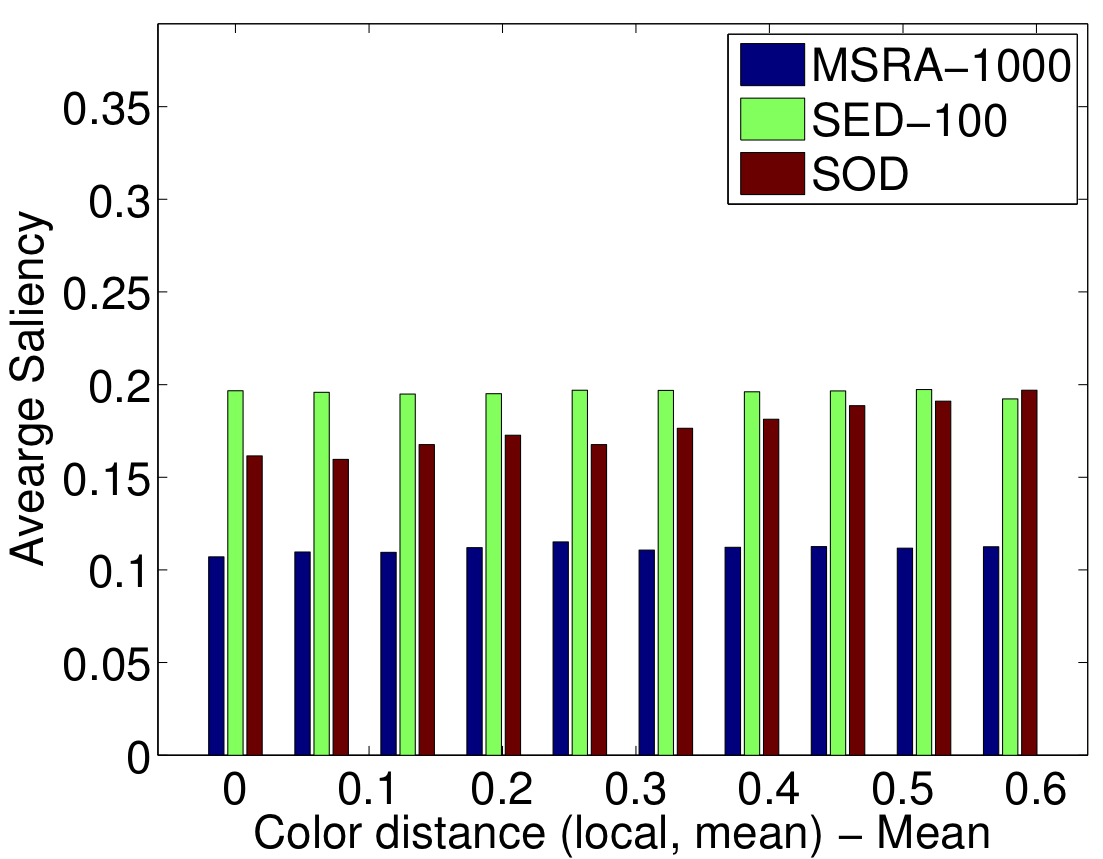
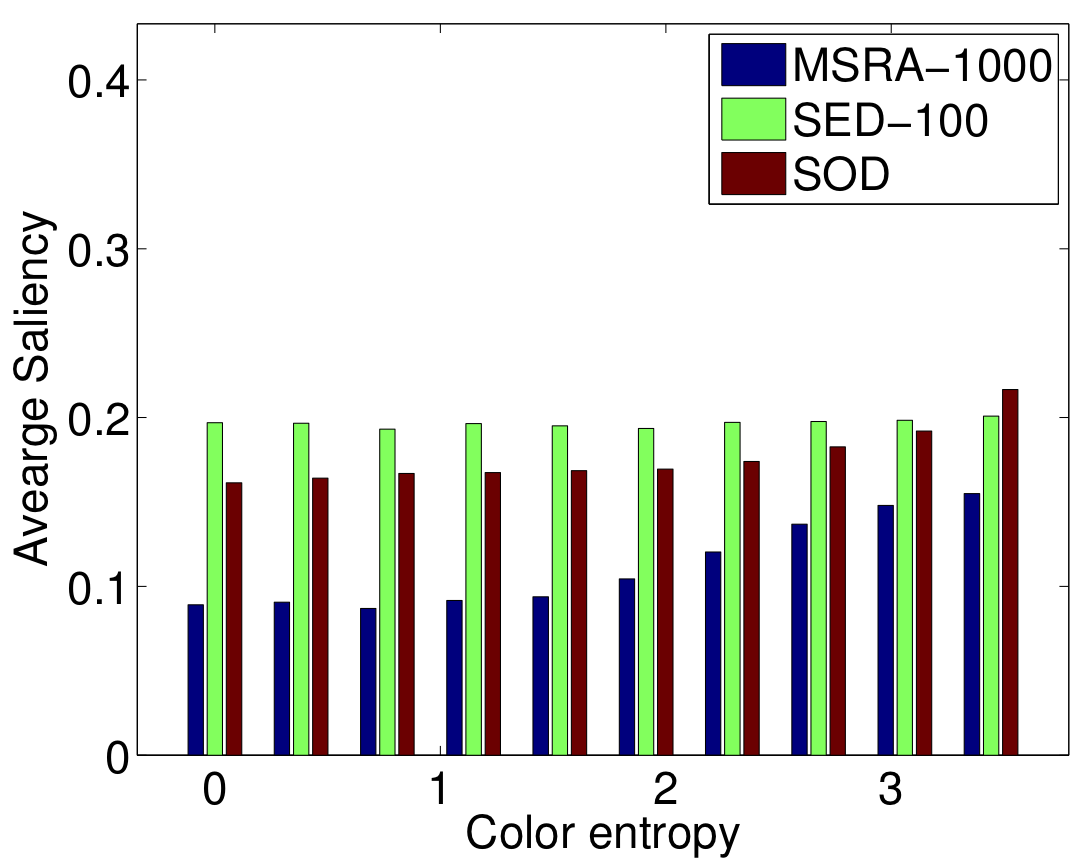
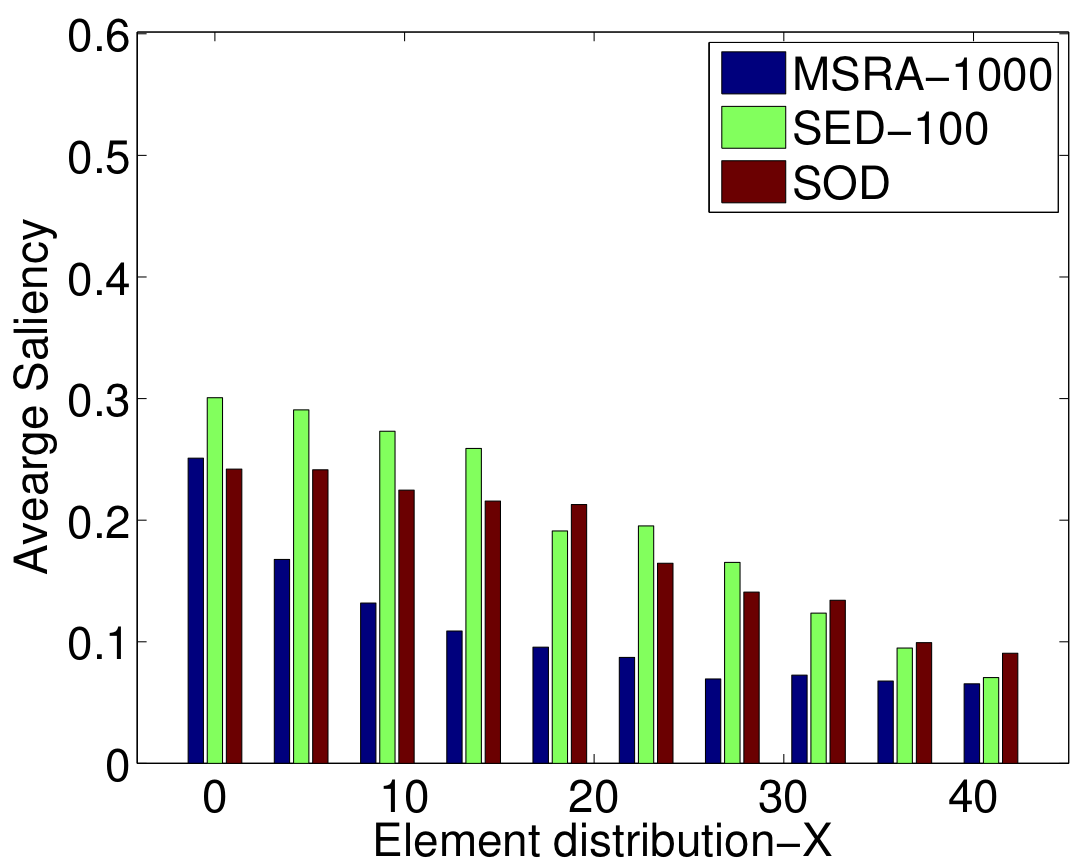
Based on the properties of the human visual system and the previous state-of-the-art methods, we choose the visual features in Table 1. We extract a feature vector from each superpixel at each hierarchy level. We have 41 features in total.
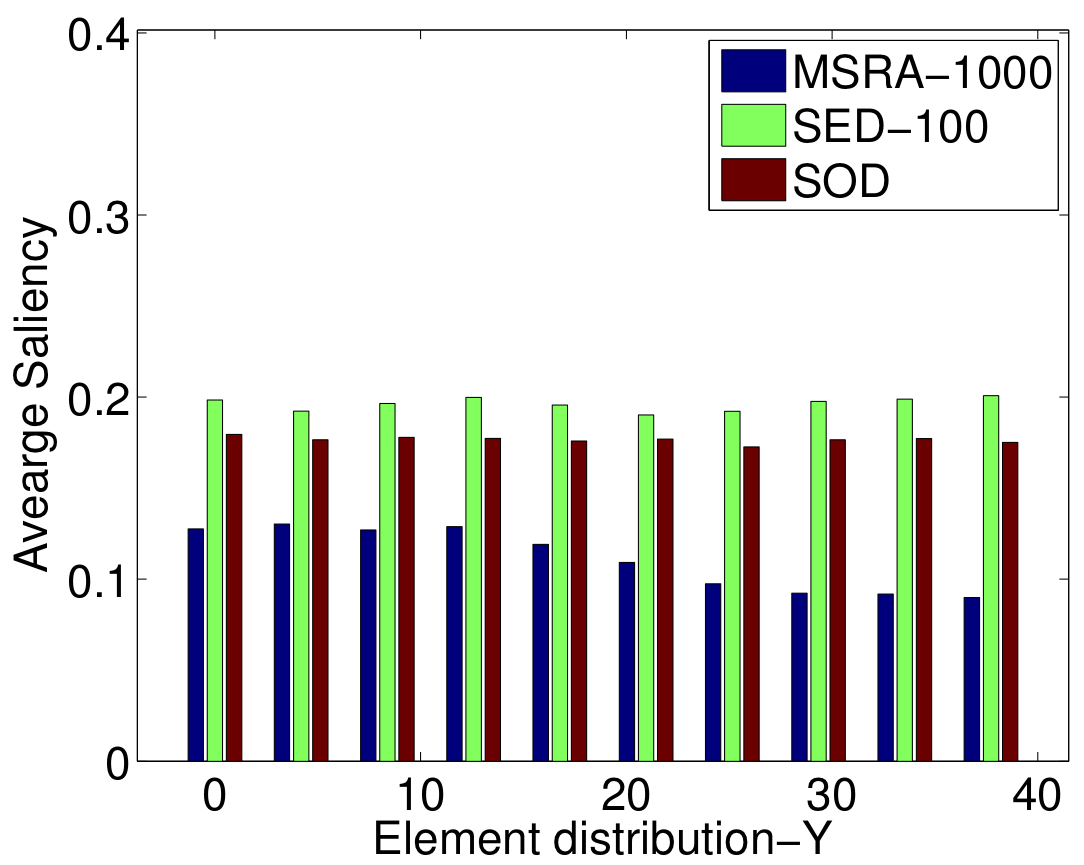
The importance of a feature is correlated to how frequently it is selected for thresholding on the nodes of regression trees. In Figure 3, the five most frequently selected features for the MSRA-1000 [1], SED-100 [2], and SOD [3] datasets are illustrated.
 |
|
| (a) | |
 |
 |
| (b) | (c) |
 |
 |
| (d) | (e) |
Results
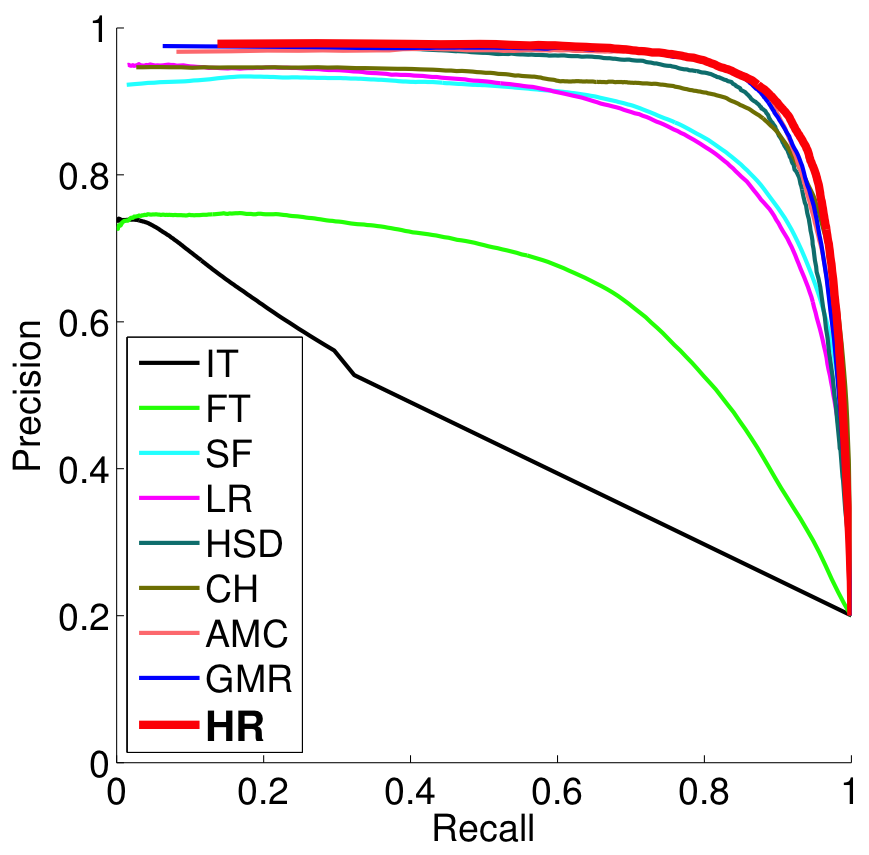
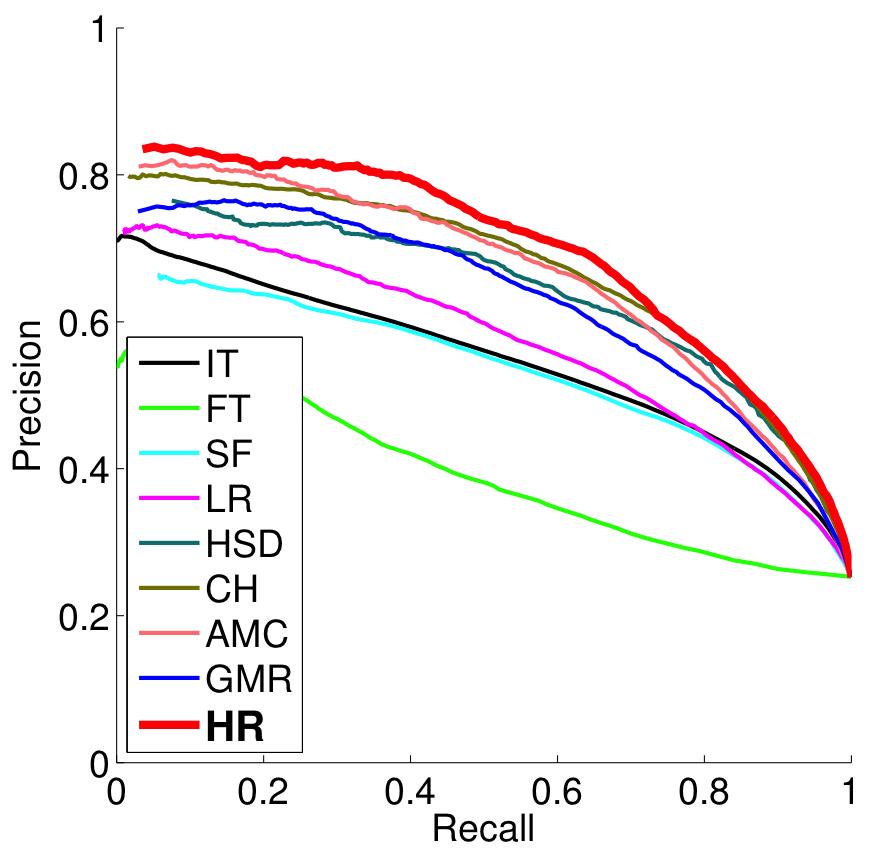
We evaluate the performance of our method, HR (Hierarchical Regression), on the MSRA-1000, the SED-100, and the SOD datasets. The precision-recall curves of our method are compared to eight other techniques (the results are obtained using their codes), which are IT , FT , SF , LR , HSD , CH [4], GMR [5], and AMC [6] in Figure 5. We mainly focus our discussions on the best performing tech- niques, which are CH, GMR, and AMC. On the MSRA-1000 dataset, we are marginally better than the other methods, as the performance of that dataset is overfitted and noisy labeling does not allow further significant improvements. On the other two datasets, our method outperforms the state-of-the-art techniques. Instead of defining heuristic rules, our algorithm learns the saliency from a group of images and successfully transfers this knowledge to other images. Regression trees effectively form complicated functions that are otherwise not so easy.
 |
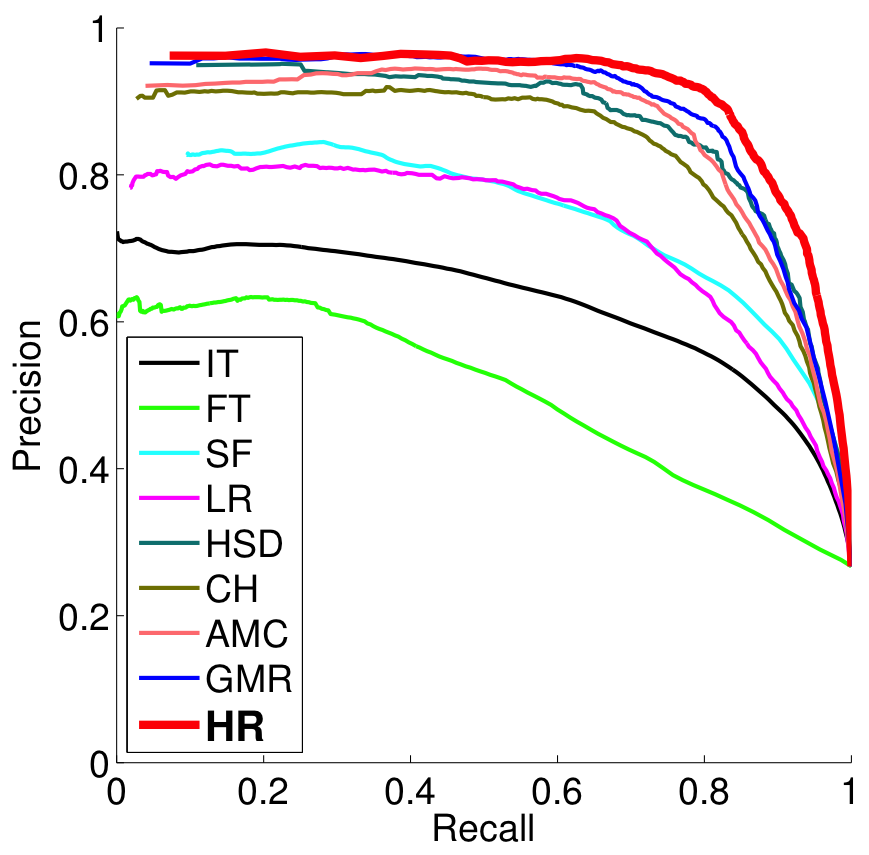 |
| (a) MSRA-1000 | (b) SED-100 |
 |
|
| (c) SOD | |
|
Original |
GT | HR | AMC | GMR | CH |
 |
|||||
| (d) Visual comparisons (GT: Ground Truth) | |||||
Figure 4: (a – c) Precision and recall curves of various methods evaluated on the MSRA-100, SED-100, and SOD dataset. (d) Visual comparisons of the generated saliency maps.
References
[1] R. Achanta, S. Hemami, F. Estrada, and S. Süsstrunk, “Frequency-tuned salient region detection,” in Proceedings of IEEE CVPR, 2009, pp. 1597 – 1604.
[2] S. Alpert, M. Galun, R. Basri, and A. Brandt, “Im- age segmentation by probabilistic bottom-up aggregation and cue integration,” in Proceedings of IEEE CVPR, 2007, pp. 1–8.
[3] V. Movahedi and J. H. Elder, “Design and perceptual validation of performance measures for salient object segmentation,” in Proceedings of IEEE CVPR Work- shops
[4] X. Li, Y. Li, C. Shen, A. Dick, and A. van den Hengel, “Contextual hypergraph modelling for salient object detection,” Proceedings of IEEE ICCV, 2013.
[5] C. Yang, L. Zhang, H. Lu, X. Ruan, and M. Yang, “Saliency detection via graph-based manifold ranking,” in Proceedings of IEEE CVPR, 2013, pp. 3166–3173.
[6] B. Jiang, L. Zhang, H. Lu, M. Yang, and C. Yang, “Saliency detection via absorbing markov chain,” Proceedings of IEEE ICCV, 2013.