Regression is used everywhere around us. Want to estimate human pose? Regression. Wish to perform depth estimation? Regression. How about generating images? Regression.
We do regression. A little bit better.
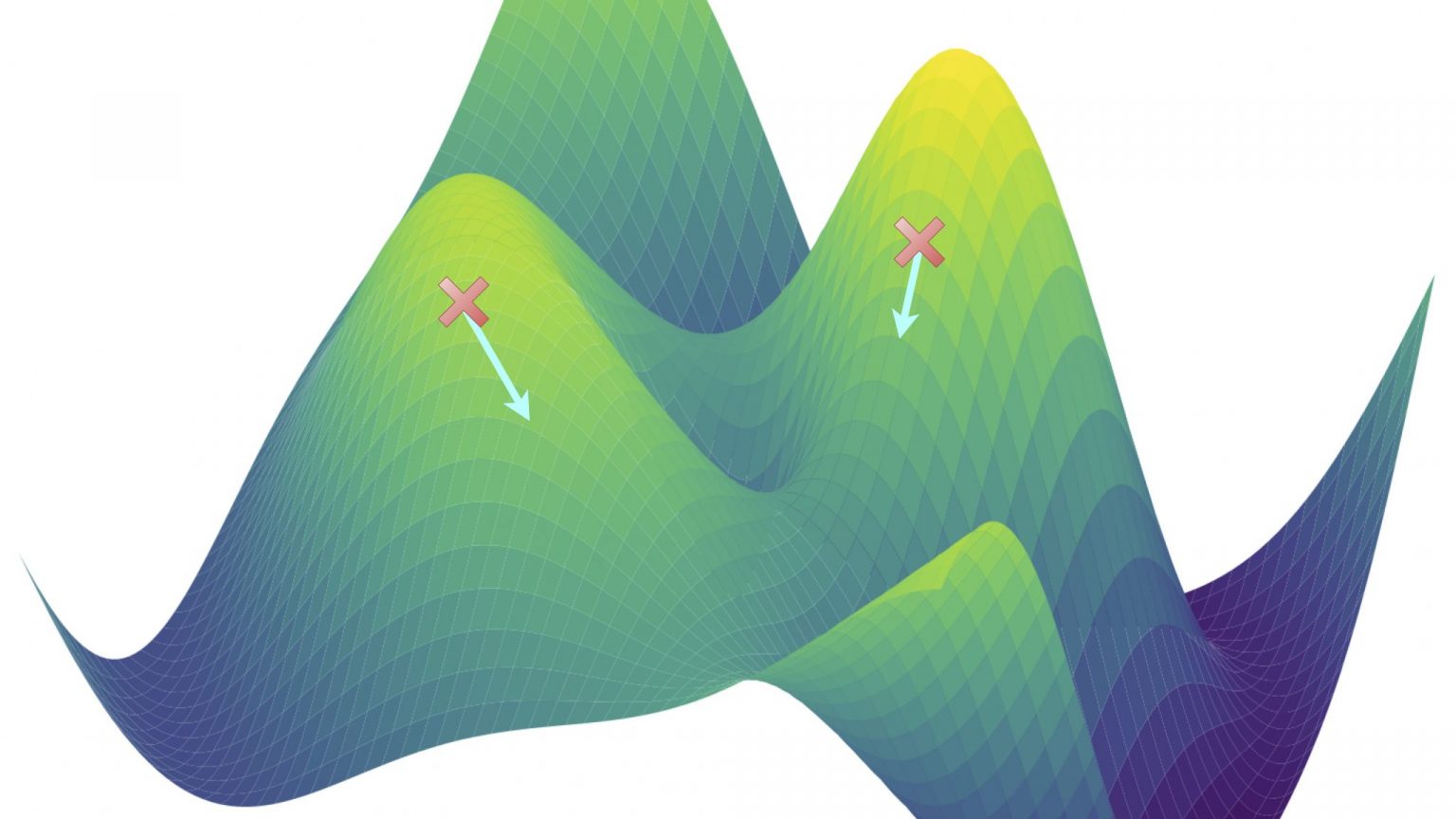
We study methods to improve deep heteroscedastic regression. Here, we show the Taylor Induced Covariance, which captures the randomness in our prediction through its gradient and curvature.
- Regression
- Regression involves predicting a set of continuous valued variables. Some common examples include predicting the weight of a person given the height or estimating the price of a house given its attributes. Examples in computer vision include human pose estimation and depth estimation.
- Heteroscedastic Regression
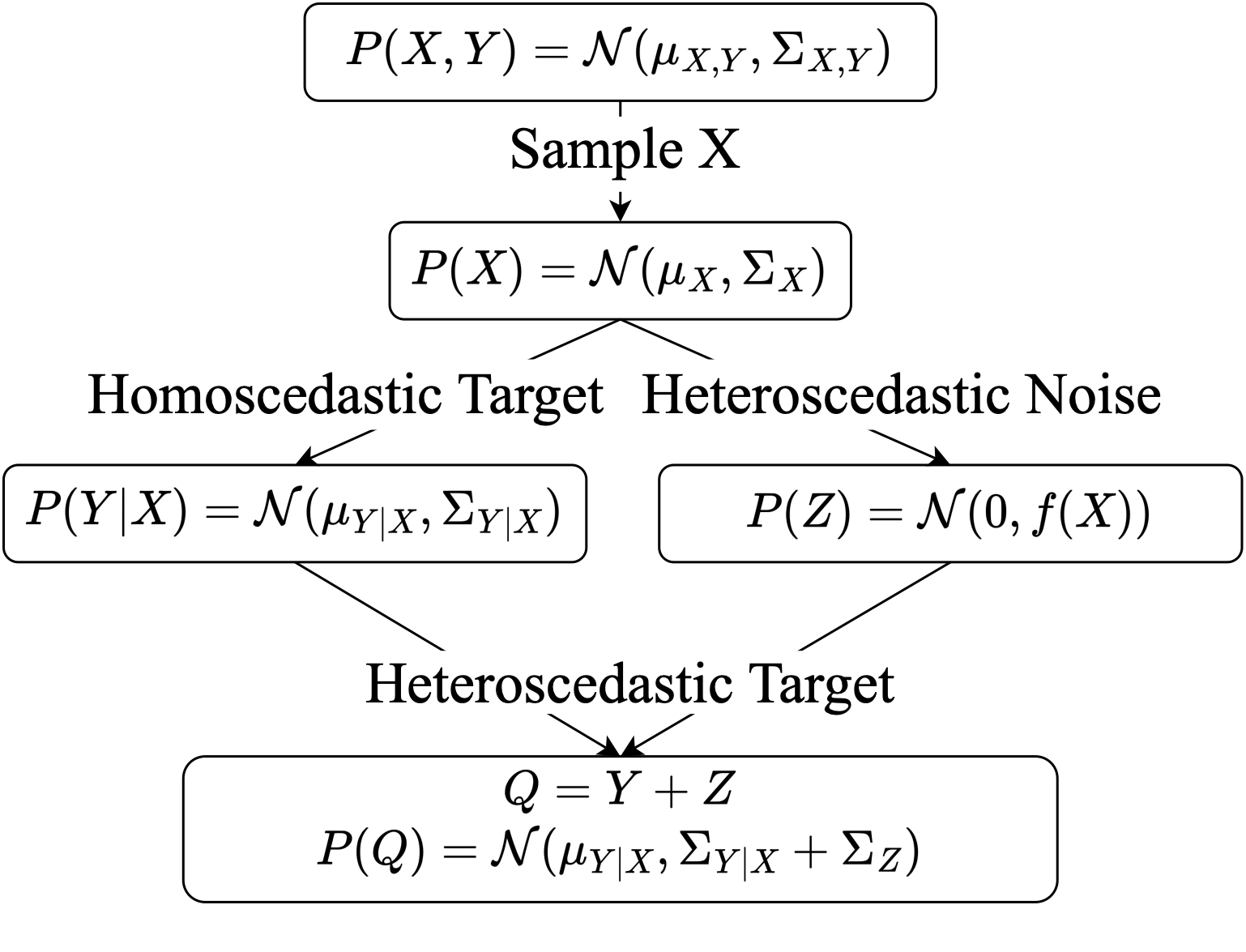
- More often than not, our data exhibits some degree of variance. This is addressed through homoscedastic and heteroscedastic regression, which provide a framework to model this variance in our data. While homoscedastic regression assumes that the variance for a given sample is independent of the sample, heteroscedasticity assumes that the variance depends on the sample.
- Deep Heteroscedastic Regression
- Deep Heteroscedastic Regression uses neural networks for heteroscedastic regression. While there are many approaches to heteroscedastic regression, deep heteroscedastic regression has significant advantages. One advantage is the ability to extract complex features from a wide variety of input types such as images and text.
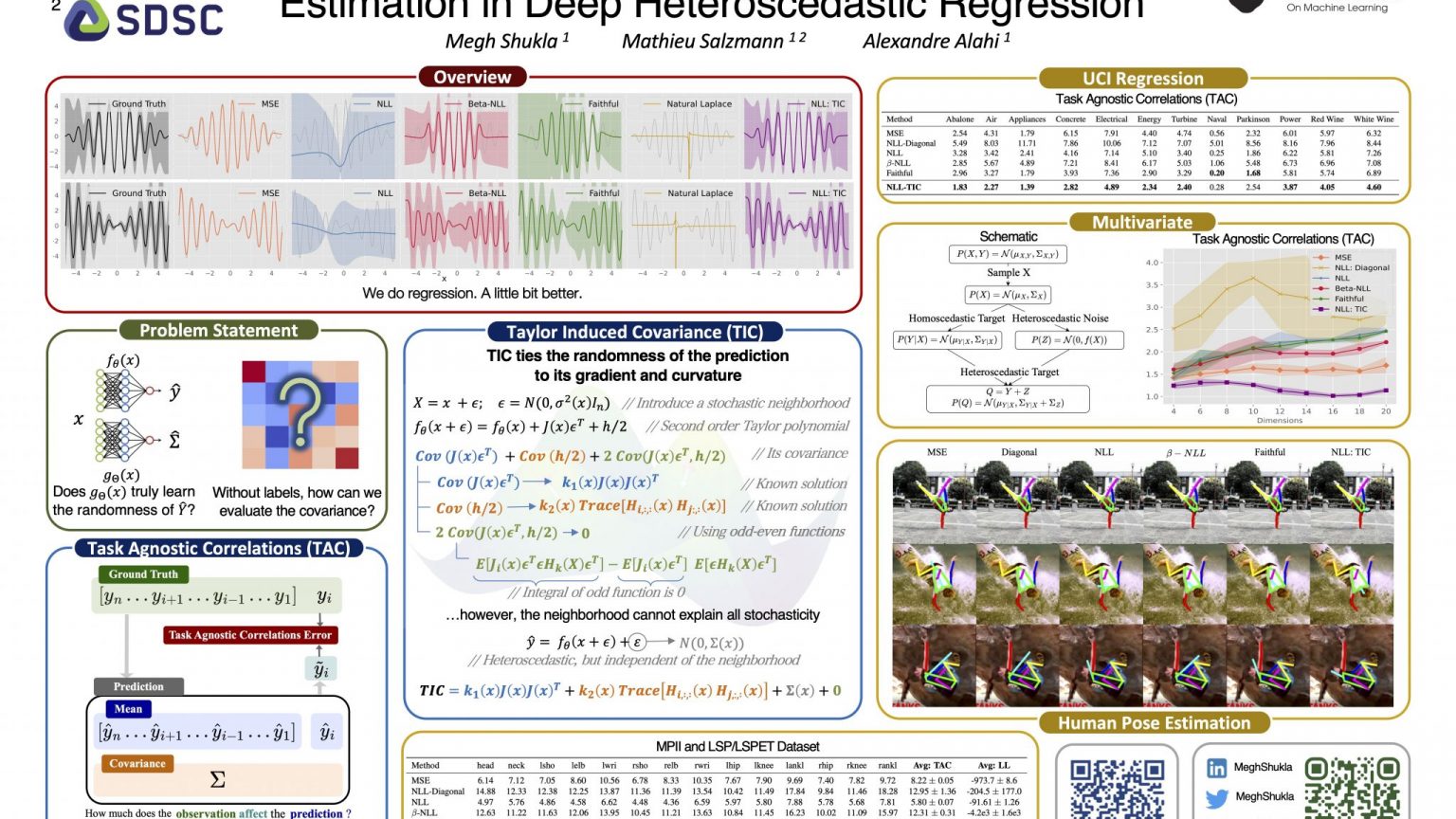
TIC-TAC Poster presented at ICML 2024
Problem Statement
Deep heteroscedastic regression learns the mean and (co-)variance of the prediction through two neural networks. This is typically learnt by jointly optimising the networks to minimise the negative log-likelihood. However, recent results show that this leads to sub-optimal convergence.
We argue that this happens because the network that estimates the covariance does not truly learn the randomness of the prediction. Indeed, without supervision, the predicted (co-)variance may be arbitrary and incorrectly minimises the likelihood.

Taylor Induced Covariance (TIC)
With TIC, we propose a new method to parameterise the covariance. Specifically, TIC ties the randomness of the prediction to its gradient and curvature. We do this by representing the input using a stochastic neighbourhood, allowing us to take the second order Taylor polynomial. We solve for the covariance of this polynomial to obtain our formulation for TIC. We describe this through an algorithm:

Task Agnostic Correlations (TAC)
While we have a new method for covariance estimation, how do we evaluate the covariance? With TAC, we propose a new metric to directly evaluate the covariance. Specifically, we reason that the goal of estimating the covariance is to encode the relation between the target variables. Therefore, partially observing a set of correlated targets should improve the prediction of the hidden targets since by definition the covariance encodes this correlation. TAC measures this improvement as an accuracy measure for the learnt correlations.
Moreover, TAC and the log-likelihood are complementary: while log-likelihood is a measure of optimisation, TAC is a measure of accuracy of the learnt correlations.


Results
We conduct experiments across real and synthetic datasets, spanning univariate and multivariate analysis. Our results show that TIC not only accurately learns the covariance, but also leads to improved convergence of the negative log-likelihood.



We learn constant and varying amplitude sinusoidal with heteroscedastic noise. We observe that TIC accurately learns the variance and improves convergence of the negative log-likelihood.

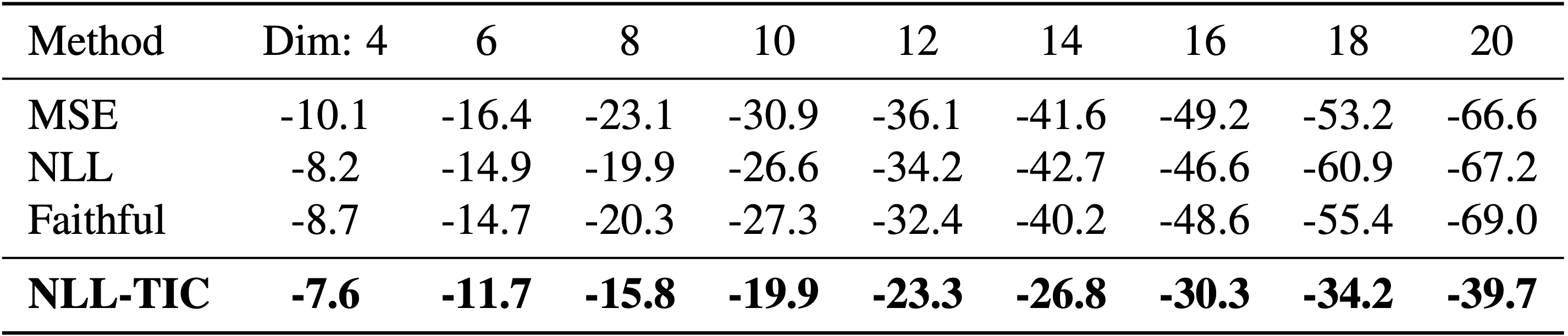
We synthesise multivariate samples with heteroscedastic noise, and show that as the dimensionality increases, the gap between TIC and other methods widens.
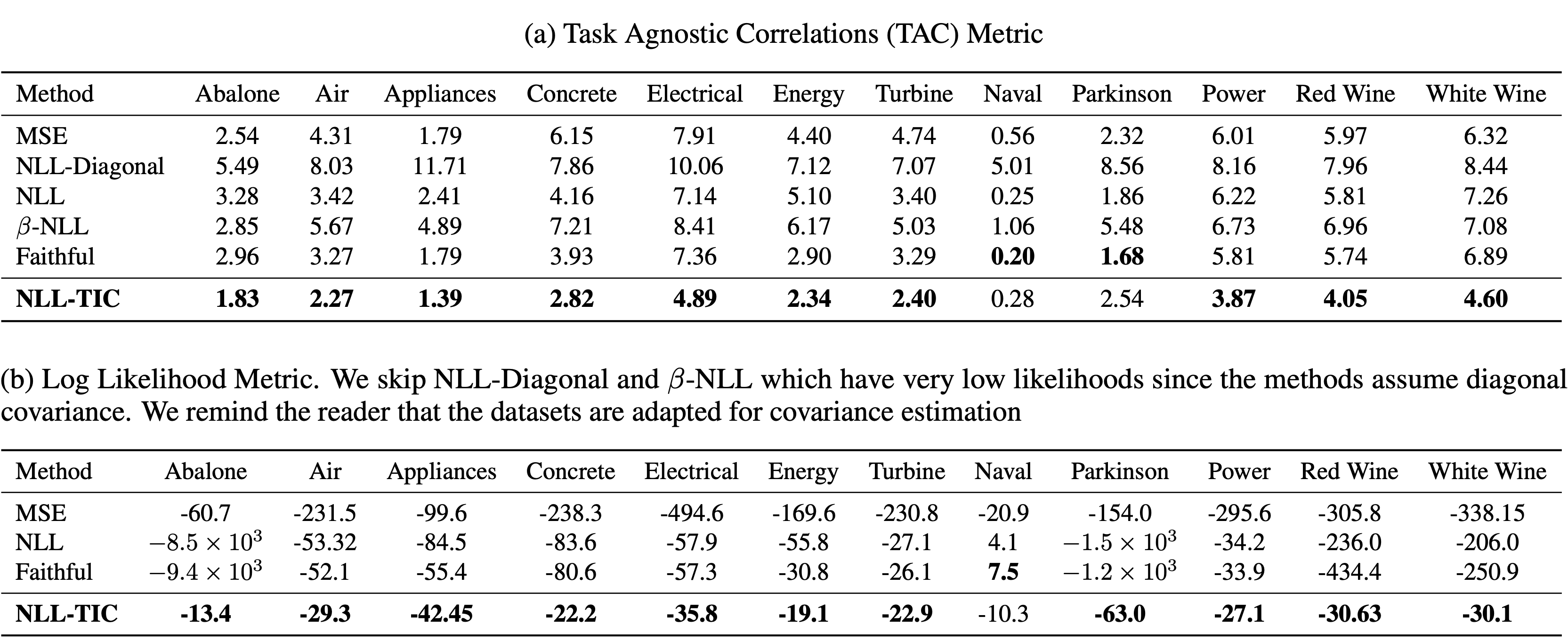
We conduct experiments on datasets from the UCI Regression repository, and report significant performance gains on most datasets. A curious observation can be made with the Naval dataset, where TIC does not perform as well as other baselines. We note that TIC may not be suitable if all samples have a low degree of variance. A low degree of variance (as indicated by the likelihood) results in accurate mean fits, which implies that small gradients are being backpropagated, and in turn affecting the TIC parameterization. However, we argue that datasets with a small degree of variance may not benefit from heteroscedastic modelling.

We use two architectures: ViTPose and Stacked Hourglass for our studies in human pose estimation.
We provide qualitative and quantitative results and show that TIC accurately learns the correlations underlying various human joints.

Acknowledgment
We thank the reviewers, for their valuable comments and insights. We also thank Reyhaneh Hosseininejad for her help in preparing the paper.
This research is funded by the Swiss National Science Foun- dation (SNSF) through the project Narratives from the Long Tail: Transforming Access to Audiovisual Archives (Grant: CRSII5 198632). The project description is available on: https://www.futurecinema.live/project/
Publication
TIC-TAC: A Framework for Improved Covariance Estimation in Deep Heteroscedastic Regression
2024. 41st International Conference on Machine Learning (ICML) 2024, Vienna, Austria, July 21-27, 2024.Supporting Material
Citation
If our work is useful, please consider citing the accompanying paper and starring our code on GitHub!
@InProceedings{shukla2024tictac,title = {TIC-TAC: A Framework for Improved Covariance Estimation in Deep Heteroscedastic Regression},author = {Shukla, Megh and Salzmann, Mathieu and Alahi, Alexandre},booktitle = {Proceedings of the 41th International Conference on Machine Learning},year = {2024},series = {Proceedings of Machine Learning Research},month = {21--27 Jul},publisher = {PMLR}}


