The aim of Blue Brain is to establish simulation neuroscience as a complementary approach alongside experimental, theoretical and clinical neuroscience to understanding the brain by building the world’s first biologically detailed digital reconstructions and simulations of the mouse brain.
In pursuit of our goal, we have a data-driven modeling process with five main stages and many elements feeding in. These inter-disciplinary stages begin with the gathering and organizing of data through to the refinement of the models and experiments.
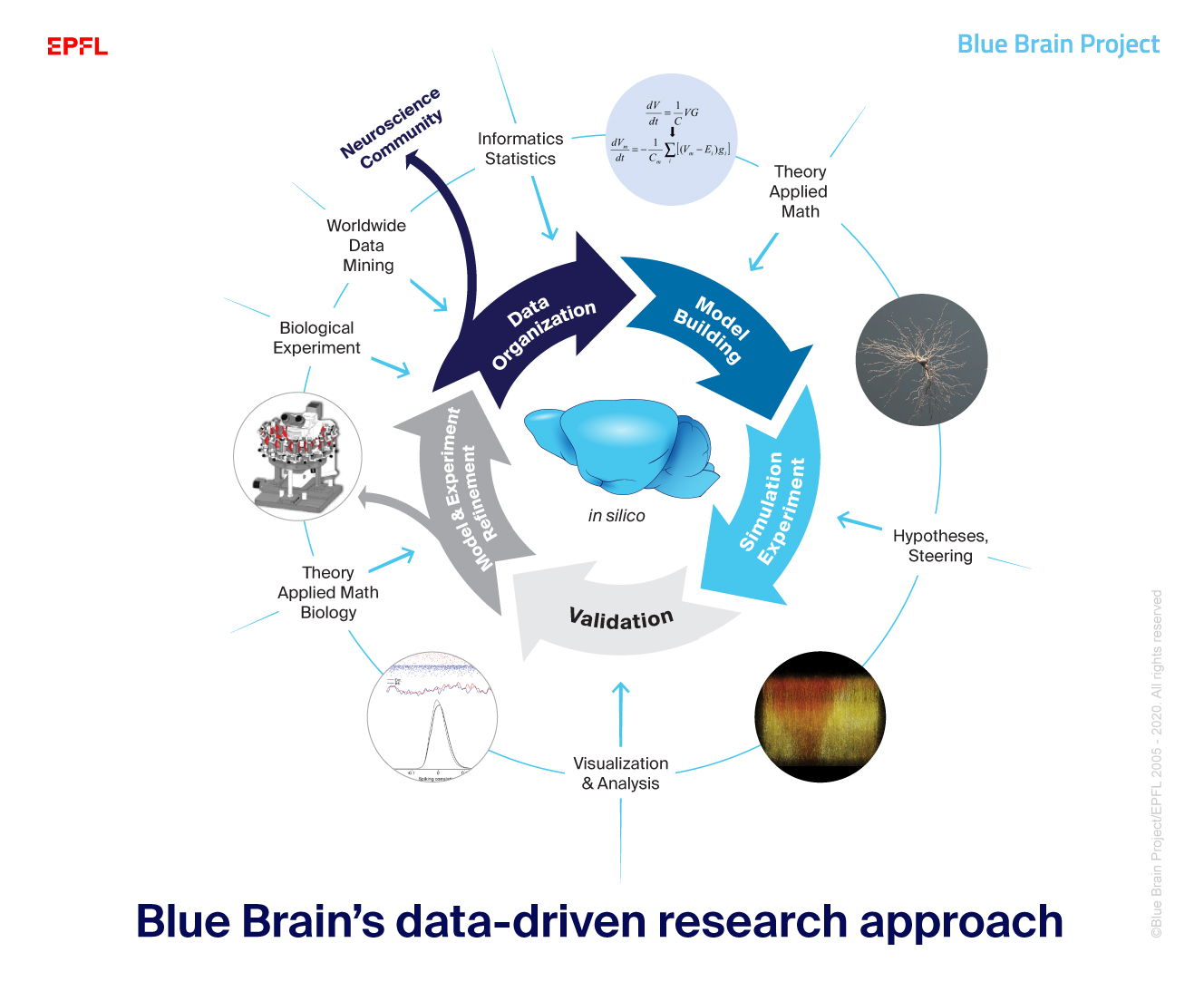
Blue Brain’s team science approach with scientists working alongside engineers, mathematicians and HPC experts supported by BBP’s architecture of software, tools and visualization abilities pertains to a vast range of in silico (simulation) predictions made with unique in silico experiments which would be infeasible or impossible in vitro or in vivo.
Read more about our research process below.
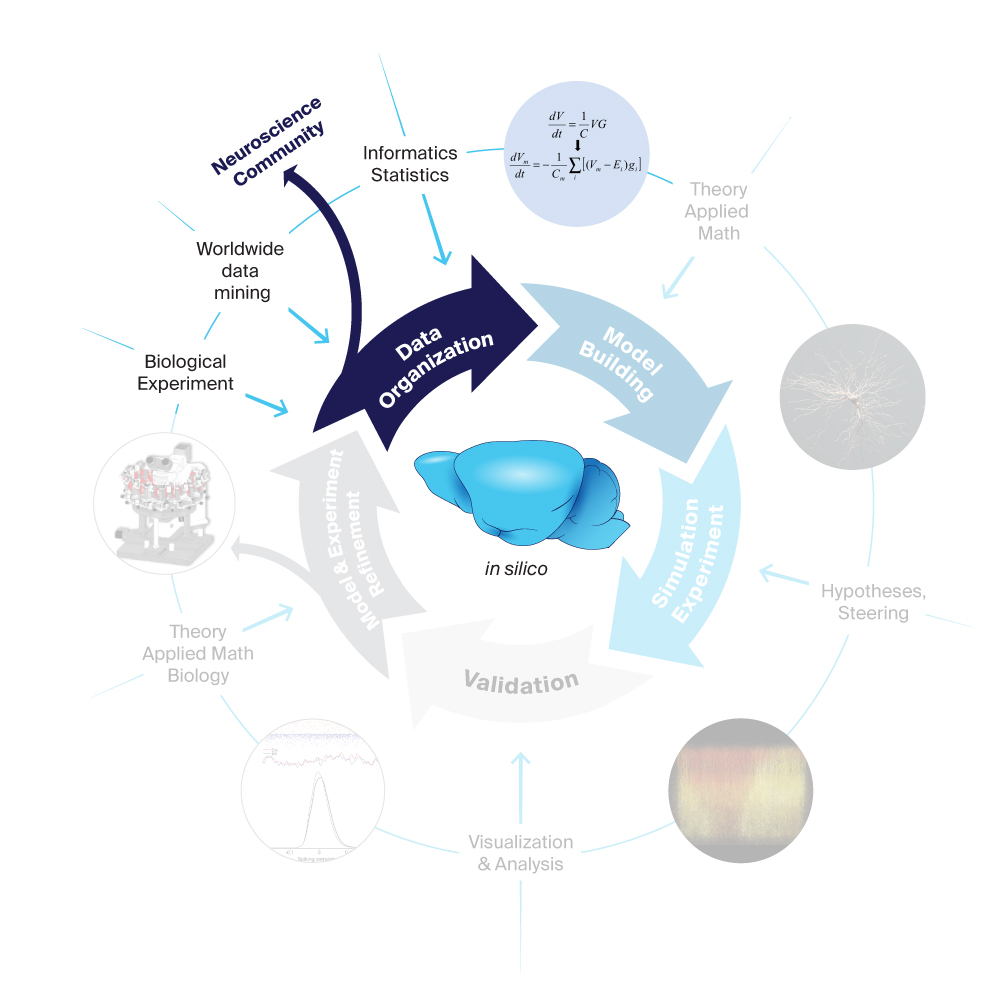
1. Data Organization
Neuroscience is a very big, Big Data challenge. The human brain for example uses over 20,000 genes, more than 100,000 different types of proteins, more than a trillion molecules in a single cell, nearly 100 billion neurons, up to 1,000 trillion synapses and over 800 different brain regions.
The first step in the Blue Brain workflow is data organization through acquisition from neuroscience experiments. We collect data describing the structural and functional organization of the brain at various levels – from synapses and subcellular components to individual neurons, to circuits and entire brain regions. Next, we extract the maximal possible information from this data and one of the project’s key strategies is to exploit interdependencies in the experimental data to build detailed, dense models from sparse data sets and employ algorithmic procedures that apply the converging constraints to fill in the missing data. In other words, we mathematically model the interdependencies to predict the missing datasets needed for a digital copy of mouse brain tissue.
This data-driven modeling approach requires an advanced and very sophisticated system for organizing, curating, atlasing, searching, and automated coupling to brain building tools. Blue Brain Nexus (open-sourced in 2018) is our state-of-the-art semantic Data and Knowledge Graph management system.
Another example of data curation at the Blue Brain is the storage and sharing of comprehensive electrophysiology data. Channelpedia is a knowledge base system centered on genetically expressed ion channel experimental data and models. The platform encourages researchers of the field to contribute, build and refine the information through an interactive wiki-like interface. It is web-based, freely accessible and currently contains 187 annotated ion channels with 45 Hodgkin-Huxley models.
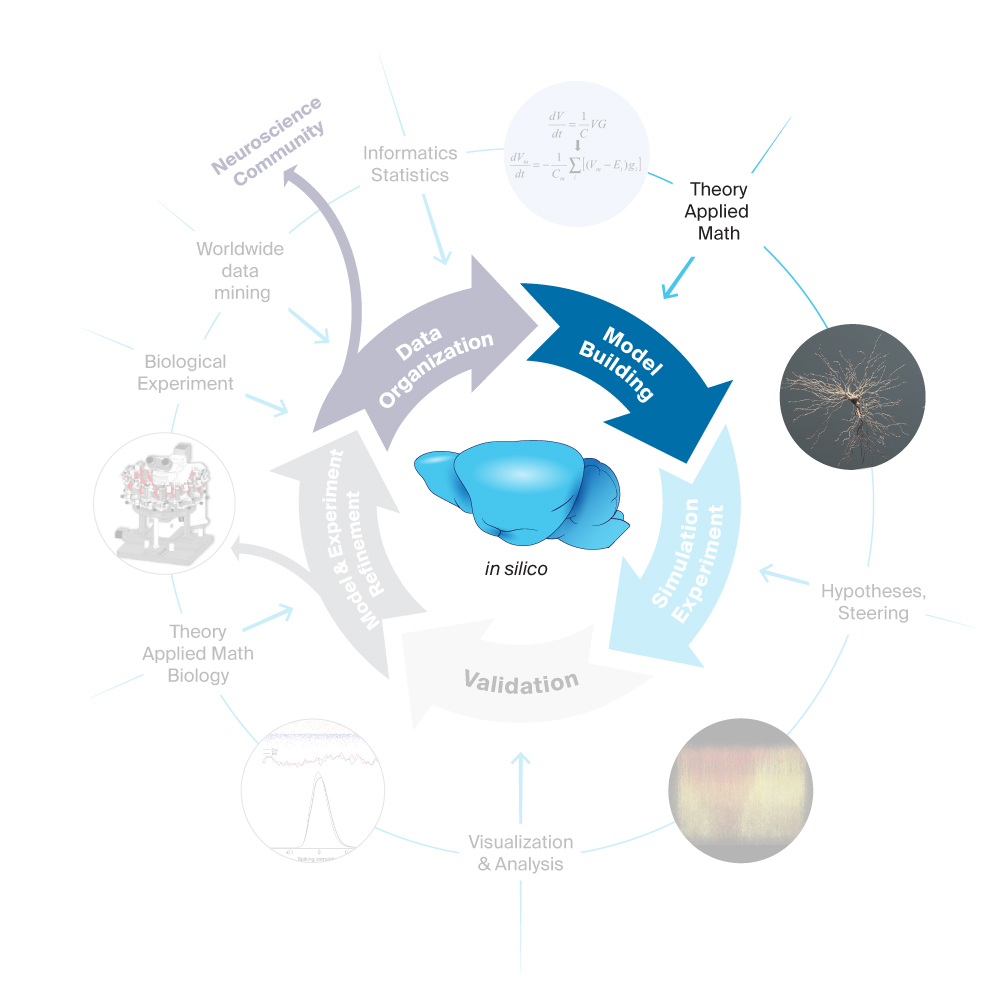
2. Model Building
Having organized the data, the next step in the Blue Brain workflow is to analyze the data and identify the principles and organization that turn the individual mechanisms into a coherent circuit (e.g. that neuron types that have a strong overlap of their axonal and dendritic trees also form synaptic connections using many synapses). We then build an algorithm that follows these biological rules to construct digital reconstructions of the brain tissue that are statistically similar to biological tissue. A digital reconstruction of the mouse brain is a mathematical model of its anatomy and physiology implemented as a computational model that can be simulated to examine the myriad of interactions. Such models aspire to an explicit geometrically and parametrically accurate representation of the brain tissue rather than an abstracted representation. We also build more abstract point neuron models that retain only the most critical biological detail by simplifying these detailed models.
Blue Brain’s digital reconstructions are formed from data at a specific age and are therefore snapshots of the structure and physiology of the brain at a given developmental stage of the brain. The reconstructions integrate the data and knowledge on molecular, cellular and circuit anatomy, and physiology (e.g., reconstructed morphologies, electrophysiological, synaptic, and connectivity models). Circuit reconstructions are built from cells and based on a standardized workflow enabled by Blue Brain Project software tools and supercomputing infrastructure. The parameterization of the tissue model is strictly based on biological data — directly, where available, generalized from data obtained in other similar systems, where unavailable, or predicted from multi-constraints imposed by sparse data.
The modeling process is highly interactive and collaborative, involving cross-functional teams from the simulation neuroscience and the computing divisions.
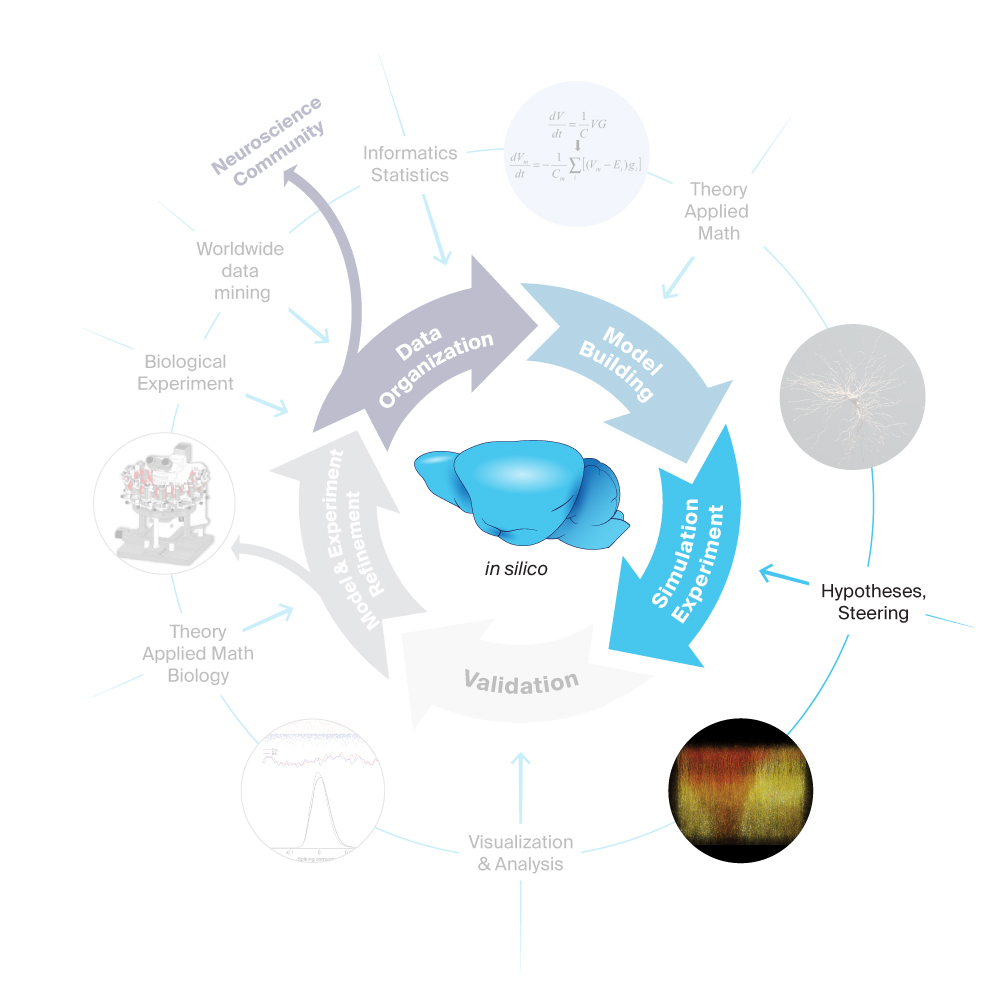
3. Simulation Experiment
An in silico experiment is a simulation of a digital reconstruction in which the stimulus and recording conditions mimic an actual biological experiment. The in silico models that the Blue Brain Project is building as part of our workflow integrate as much biophysical and biochemical detail as possible, allowing us to make predictions about the specific role of these details. Controlled manipulation of detailed mechanisms in a simulation even allows us to go beyond correlation by following causal chains of events. These models make the scientific body of data ‘active’ in the sense that scientists can exercise whether our understanding of the components is sufficient to generate a system that behaves as in experiments.
Simulations also provide powerful tools for understanding biological mechanisms beyond the reach of experimental and theoretical approaches. In silico experiments can be devised which have yet no known experimental representation, to explore new conceptual horizons and test hypotheses on emergent dynamical features against the integrated state of knowledge embodied in digital reconstructions. In this sense, simulation represents a third pillar, together with experimental and theoretical approaches, to generate knowledge in neuroscience, and is particularly suited for knowledge integration and the exploration of the mechanisms of emergent phenomena.
Pioneering simulation neuroscience has led to Blue Brain reconstructing a virtual neocortical microcircuit by integrating cellular and synaptic anatomy and physiology data, and testing its validity against an array of in vivo experiments. This reconstruction has provided a platform for many of our milestones and has greatly contributed to neuroscience and beyond.
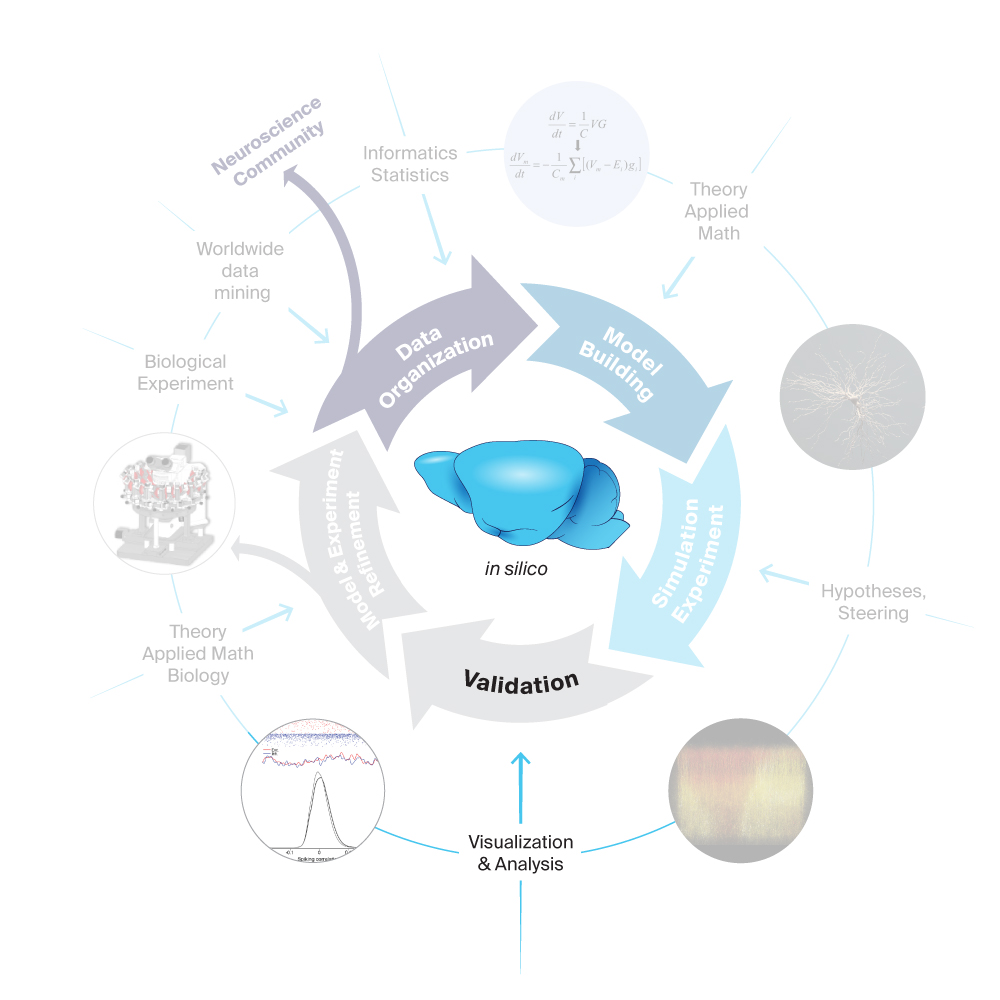
4. Validation
Blue Brain models are built by gathering data from state-of-the-art cell morphology and physiology neuroscience research. The sum of those parts – a biologically realistic model – must in turn be validated by comparing results of in silico experiments to experimental data on the behavior of real-life brain networks. An in silico experiment is a simulation in which the stimulus and recording conditions mimic an actual biological experiment.
For instance, many neuroscience experiments record the electrical activity of a brain slice or the brain of a living animal in response to electrical stimulation. The experimental manipulations and observations of such an experimental protocol can be recreated in a simulation of a comparable digital reconstruction. Such comparisons between the experimental and simulation recordings are a vital tool for validation, or more specifically assessing the domain of validity, of digital reconstructions, whereby parameters tuning to match a specific validation test is excluded.
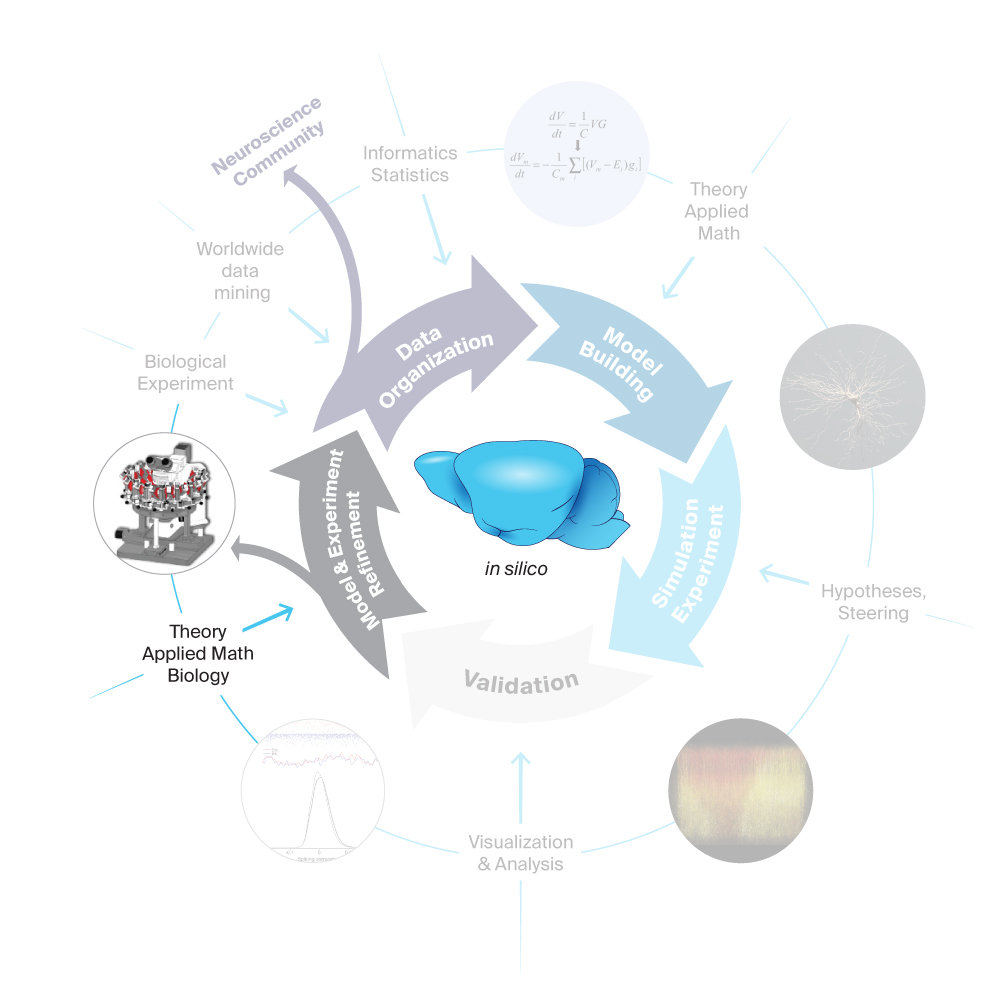
5. Model and Experiment Refinement
After the validations have established the domain of validity of a model, two types of activity logically follow: Where the model has been established to be valid, we perform simulation campaigns to generate predictions about the workings of brain networks (see step three). Where it is still invalid, we refine the model until it becomes valid.Where the results of an in-silico experiment do not match the biological data, we investigate the cause of that failure. It can be the result of faults or incompatibilities in the data used for the construction of the model. Or, it can be the result of incomplete rules or faulty assumptions used when putting the data together into a model (see step two). In both cases, we rectify and then rebuild a new iteration of the model. This cycle is repeated until the model is consistent with all the data and knowledge we have about the brain. Therefore, each time we turn the wheel of building, testing and building again, the models become more and more precise copies of regions of the mouse brain and our predictions become more and more accurate.