The RCP Cluster offers a scalable service made up of 400+ different GPUs. The servers are physically deployed in the DC2020 Datacenter.
These GPU computing services are available to all EPFL research units, including all laboratories, centers and platforms.
The service is accessible to all researchers across EPFL.
GPU-based servers, including the high-end NVIDIA GPU (H100 80 GB, A100 80 GB), and performant network connectivity (100 GbE) are used for this service offer.
Users access the service by first building their Docker image and then launching their job through a custom scheduler using the Kubernetes orchestrator.
Types of workloads
There are two different types of workloads:
|
Interactive jobs |
Train jobs |
|
|
Purpose |
Testing & Development. |
Training & Compute. |
|
Maximum GPUs |
|
Available GPUs. |
|
Maximum duration |
12 hours. |
Until job finishes. |
|
Preemption? |
No |
Yes (jobs automatically restarted). |
|
Job priority |
High |
Low |
|
Distributed workloads? |
No |
Yes |
|
Considerations |
|
|
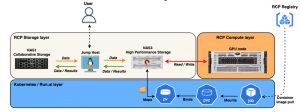
Data journey
It is worth noting that the NAS collaborative storage (NAS1) can be accessed with a QoS in this environment, this storage (NAS1) is not to be used for simulations input/output. The High-Throughput storage subsystem (NAS3) is dedicated to this.
Onboarding
The RCP team provides onboarding sessions to all new users. These sessions may be organised on request. Please contact us at supportrcp@epfl.ch
During this session we go through the different concepts and the data journey.
Some useful links
- Documentation : https://wiki.rcp.epfl.ch/en/home/CaaS
- Scheduler : https://rcpepfl.run.ai/
- Registry link :https://registry.rcp.epfl.ch/
- U1 Pricing details : https://www.epfl.ch/campus/services/finance/wp-content/uploads/2024/09/Grille-RCP-validee-1.pdf
